رؤى هندسية
التعمق في أنظمة الذكاء الاصطناعي والبنية السحابية والأنظمة الموزعة والريادة الهندسية.

Deepfake Phishing Defence — Synthetic Voice and Video Detection and Verification Architecture (2026)
Deepfake phishing defence for 2026: layered detection, C2PA content provenance, and the out-of-band callback protocol that defeats a flawless voice or video impersonation.
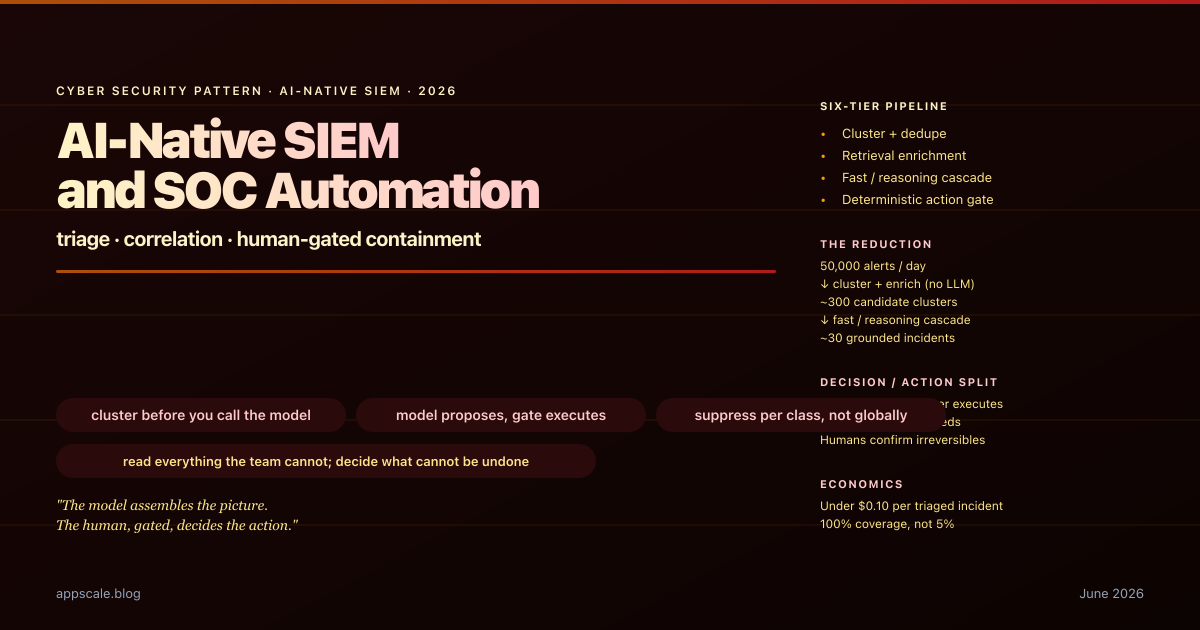
AI-Native SIEM and SOC Automation — LLM Alert Triage, Correlation, and Human-Gated Containment (2026)
AI-native SIEM for 2026: LLM clustering, correlation, and summarisation that turns 50,000 alerts into 30 grounded incidents, with a deterministic human-gated containment tier.
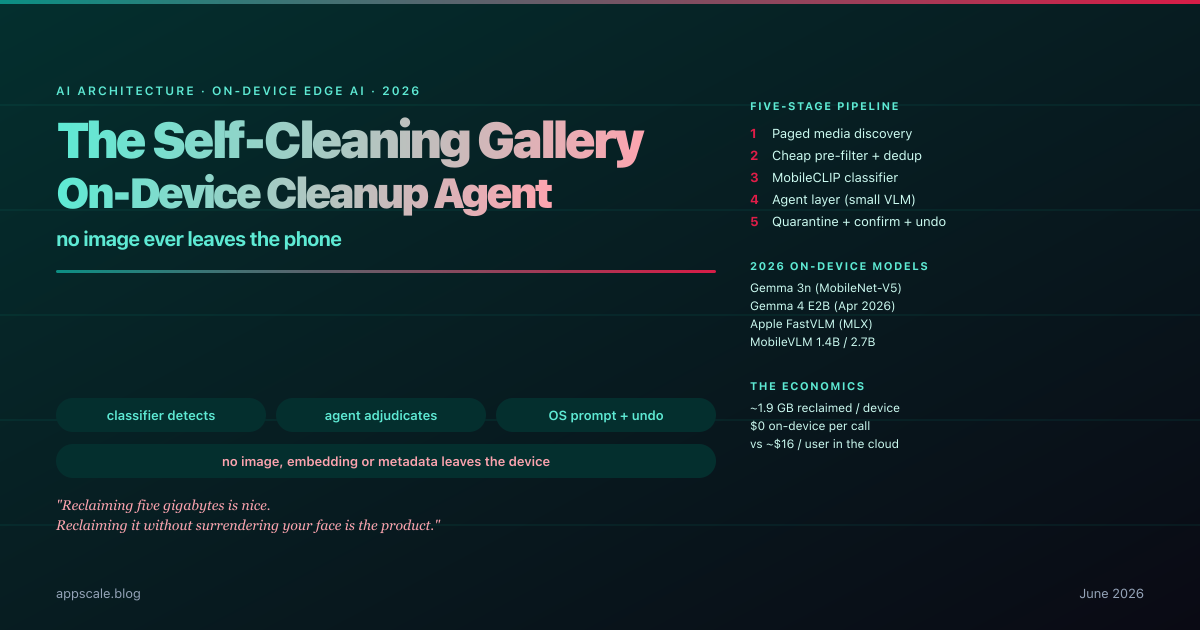
The Self-Cleaning Gallery — A Fully On-Device Agent That Reclaims Storage from Advertising Clutter (2026)
A fully on-device gallery-cleanup agent flags ad clutter with a MobileCLIP-class vision classifier, then quarantines and reclaims gigabytes — no image leaves the phone.
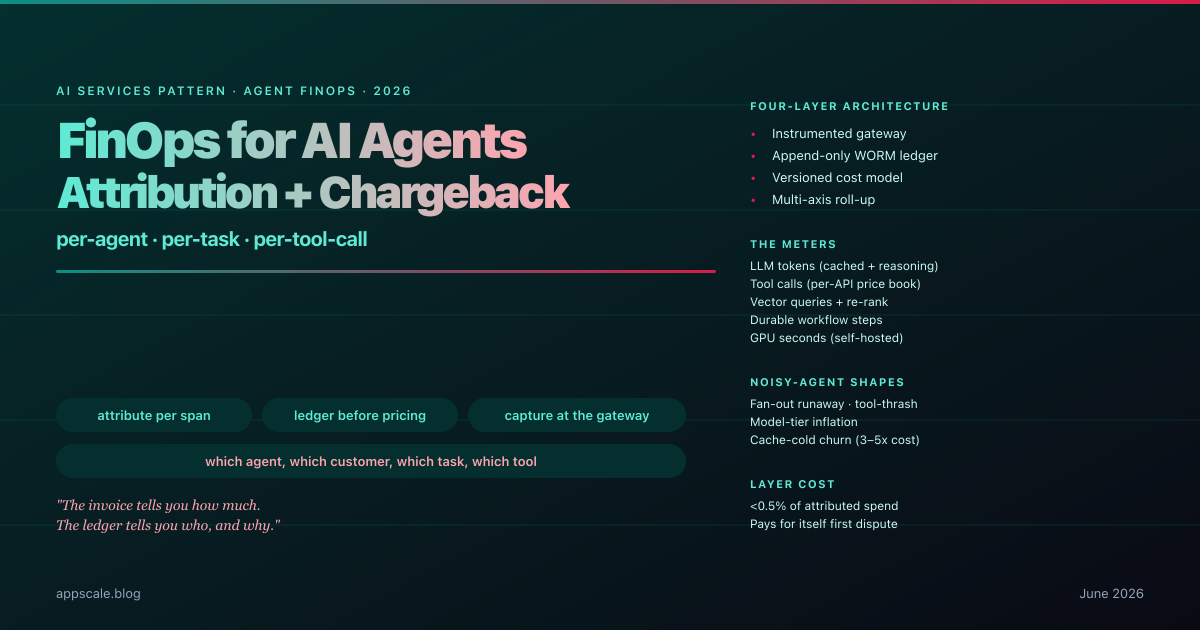
FinOps for AI Agents — Per-Agent, Per-Task, Per-Tool-Call Cost Attribution and Chargeback for Autonomous Fleets (2026)
Production agent-fleet FinOps in 2026: per-span cost attribution, append-only ledger, versioned cost model, multi-axis roll-up, noisy-agent detection, chargeback.

How a High-Throughput Payment Gateway Stays Up — Timeouts, Circuit Breakers, Sagas, Idempotency, and RPO/RTO (2026)
How a high-throughput payment gateway stays up: timeouts, circuit breakers, sagas, idempotency keys, the transactional outbox, and near-zero RPO with low RTO failover.
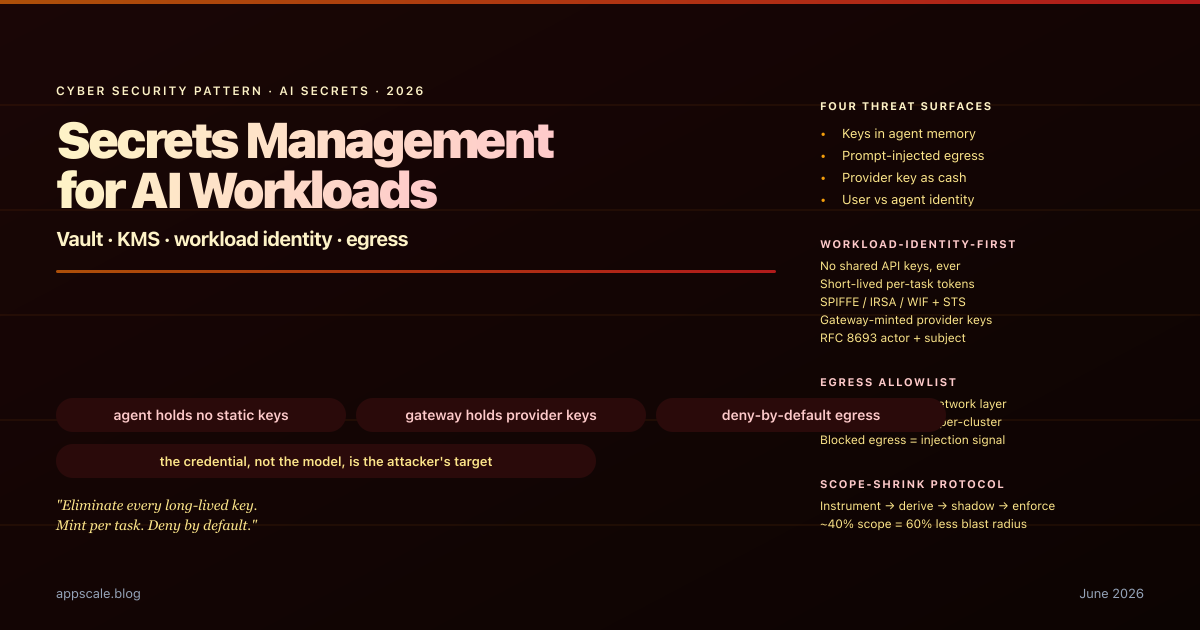
Secrets Management for AI Workloads — Vault, KMS, Workload Identity, and Per-Tool Egress Allowlists (2026)
Production secrets management for AI workloads in 2026: workload identity, no shared API keys, short-lived capability tokens, gateway-minted provider keys, and egress allowlists.

Durable Execution for LLM Agents — Temporal, LangGraph Checkpointers, and Resumable SSE (2026)
Production durable execution for LLM agents in 2026: Temporal, LangGraph checkpointers, replay-safe activities, idempotency keys, resumable SSE, HITL signals.

AI Inference Disaster Recovery — Multi-Region, Multi-Provider, and the Failover Playbook (2026)
Production AI inference DR for 2026: multi-region within provider, multi-provider with portability, hot standby per workload tier, durable checkpoints, game day.
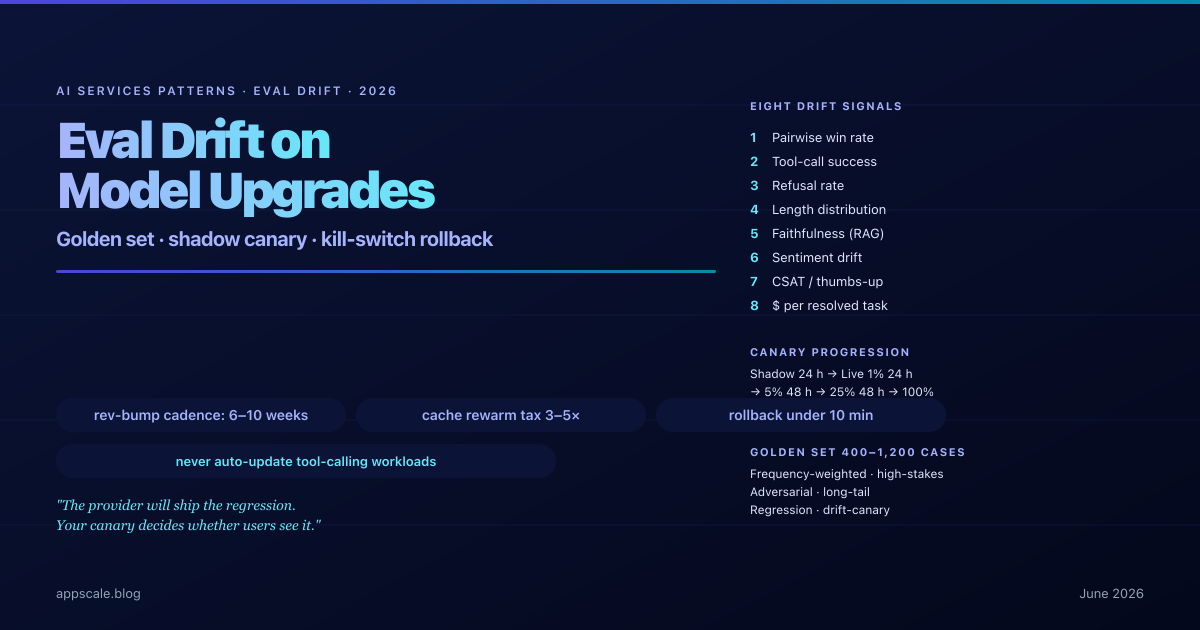
Eval Drift on Model Upgrades — Silent Regression, Canary Traffic, and Golden-Set Gates (2026)
Production playbook for eval drift on LLM upgrades: pinned snapshots, daily golden-set replay, shadow then live canary, eight signals, kill-switch rollback.
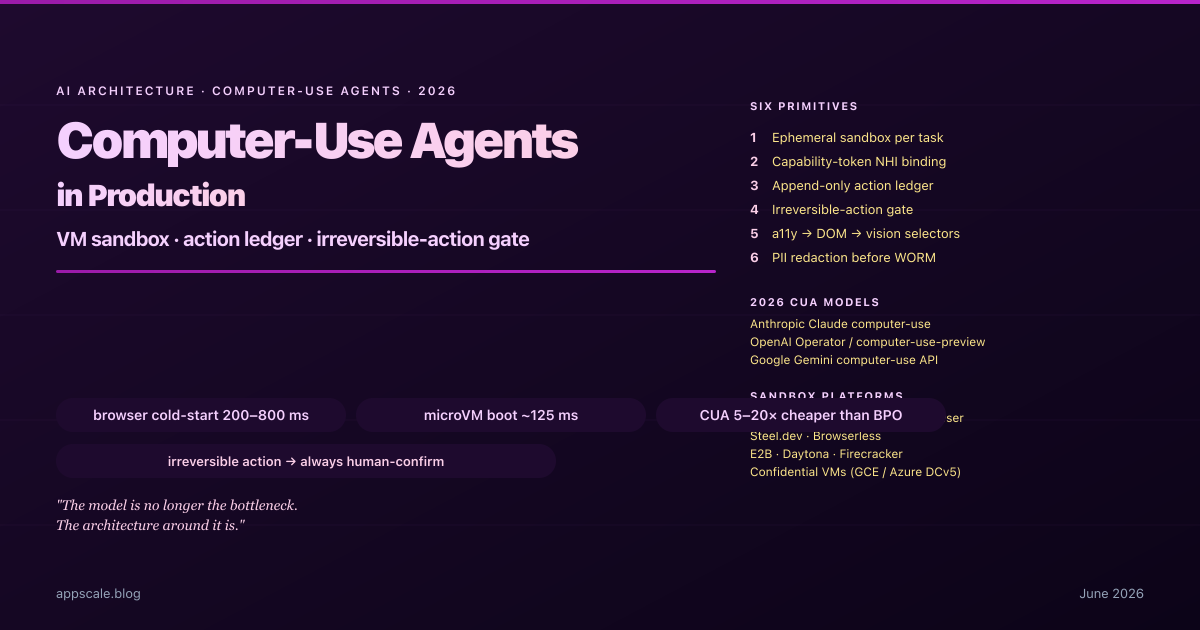
Computer-Use Agents in Production — VM Sandboxing, Action Audit, and Recovery (2026)
Production architecture for computer-use agents in 2026: VM-per-task sandboxing, action ledger, irreversible-action gate, selector resilience, and eval drift.

Non-Human Identity for AI Agents — Workload Identity, Capability Tokens, and the End of the Shared Service Account (2026)
Non-human identity for AI agents in 2026: workload identity, RFC 8693 capability tokens, on-behalf-of delegation, scope policy engine, and rotation discipline.

Backend-for-Frontend (BFF) in Production — GraphQL Federation, tRPC, and Edge BFFs Without the Anti-Patterns (2026)
Backend-for-Frontend in 2026: one BFF per client experience, GraphQL Federation vs tRPC vs REST per client-shape, Edge BFFs, and eight production anti-patterns.
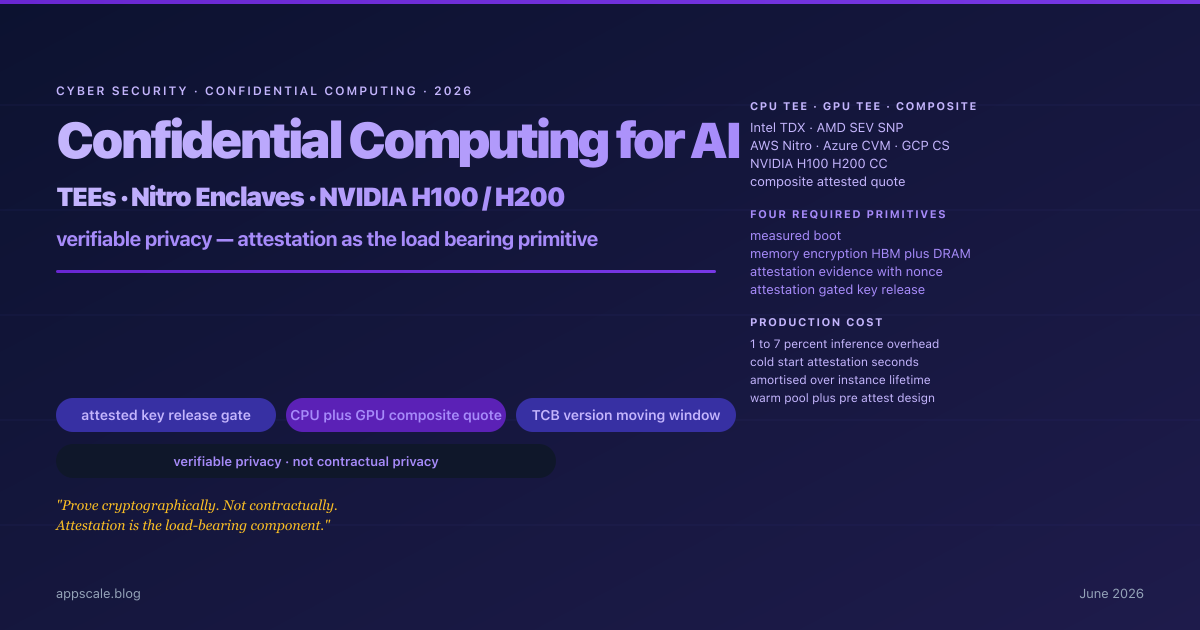
Confidential Computing for AI Inference in 2026 — TEEs, Nitro Enclaves, NVIDIA H100/H200, and the Verifiable-Privacy Architecture
Confidential computing for AI inference in 2026: CPU TEEs, NVIDIA H100/H200 GPU CC, attestation-gated key release, and the verifiable-privacy architecture procurement now demands.
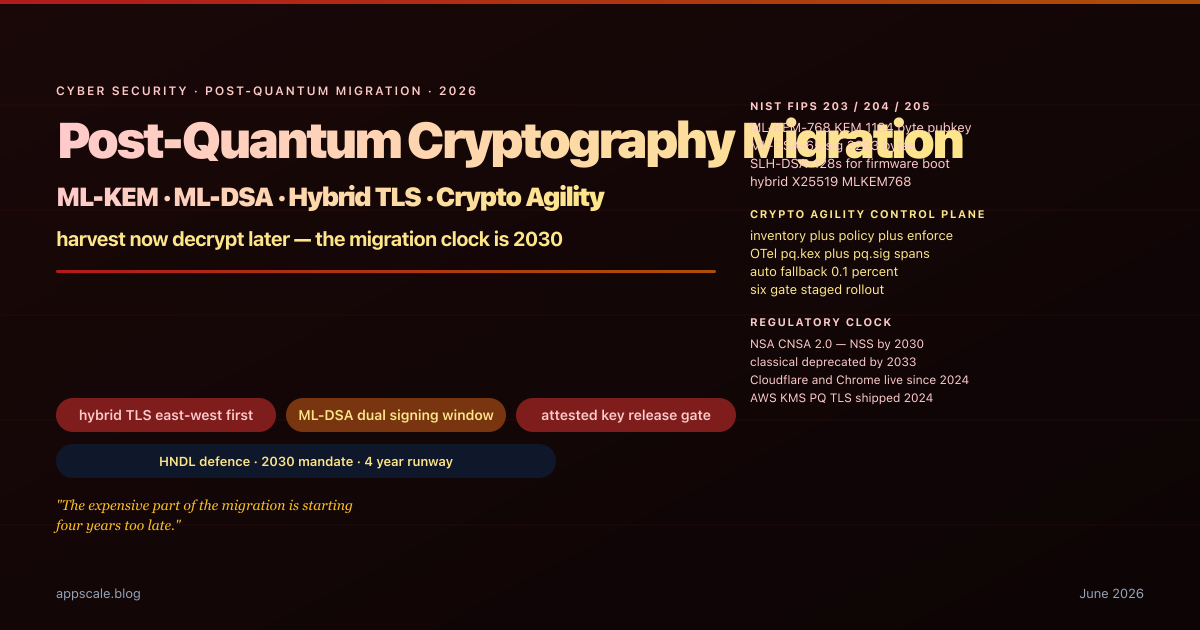
Post-Quantum Cryptography Migration in 2026 — ML-KEM, ML-DSA, and Hybrid TLS for Production Systems
Post-quantum migration in 2026: ML-KEM, ML-DSA, hybrid TLS, the crypto-agility control plane, and the six-gate rollout that survives production at NSA-CNSA-2 timelines.
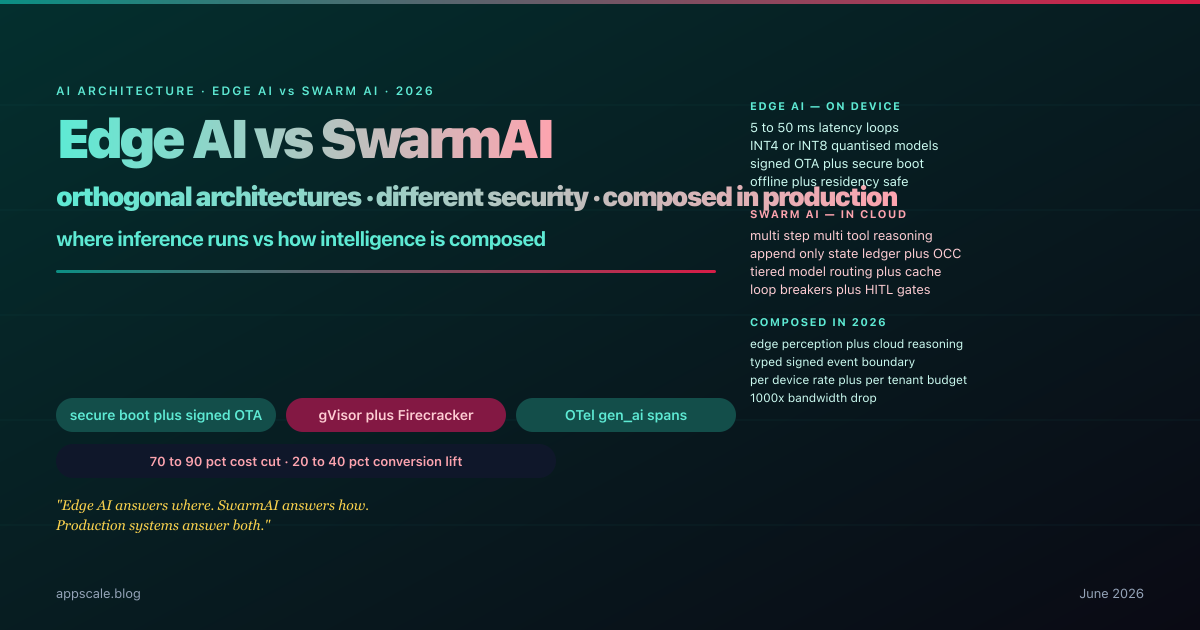
Edge AI vs SwarmAI — Differences, Security, Adoption, and Business Plus Consumer Benefits (2026)
How Edge AI and SwarmAI differ in 2026, the security threat models for each, adoption sequencing, and the business plus consumer benefits when systems compose both.

Production SwarmAI Systems — Architecture, State, Guardrails, and Observability for Multi-Agent Platforms (2026)
How production SwarmAI platforms split into eight tiers, bound emergence with loop-breakers, route across model tiers, and cut costs by 90 percent without quality loss in 2026.
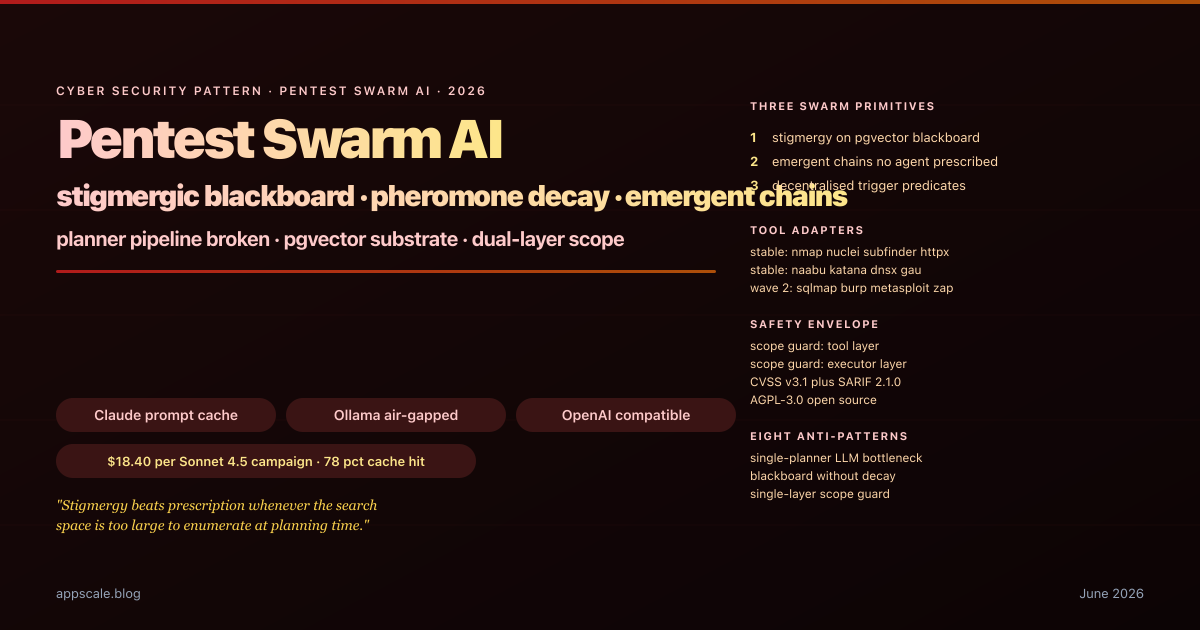
Pentest Swarm AI — Stigmergic Blackboard Architecture for Autonomous Penetration Testing (2026)
How Pentest Swarm AI replaces planner-LLM pipelines with a pgvector blackboard, pheromone-weighted findings, dual-layer scope guards, and trigger-predicate dispatch in 2026.

Event Sourcing in Production — Snapshots, Projections, and Schema Evolution Without Tears (2026)
Event sourcing for production microservices in 2026 — aggregate boundaries, append-only stores, snapshot strategy, projection rebuilds, and schema evolution.
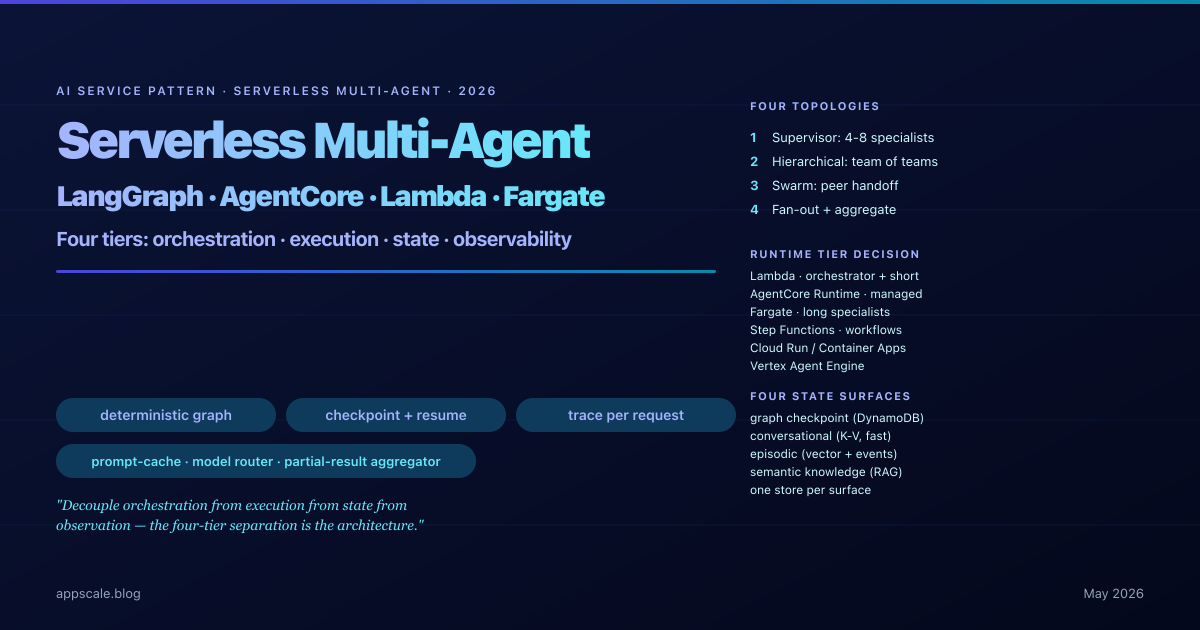
Serverless Multi-Agent Orchestration — LangGraph, Bedrock AgentCore, and the Architecture Pattern Behind Production AI Workflows (2026)
2026 pattern for serverless multi-agent systems: LangGraph orchestration, Bedrock AgentCore, fan-out topologies, four-tier state, per-span observability.

Streaming LLM Response Pattern — SSE, WebSockets, Structured Output, and Backpressure (2026 Architecture)
The 2026 production architecture for LLM streaming: SSE versus WebSockets, structured output, backpressure, end-to-end cancellation, TTFT levers, and proxy buffering.
ابق في صدارة المنحنى
التعمق الأسبوعي في أنظمة الذكاء الاصطناعي والبنية السحابية والأنظمة الموزعة والقيادة الهندسية. انضم إلى أكثر من 5000 مهندس.