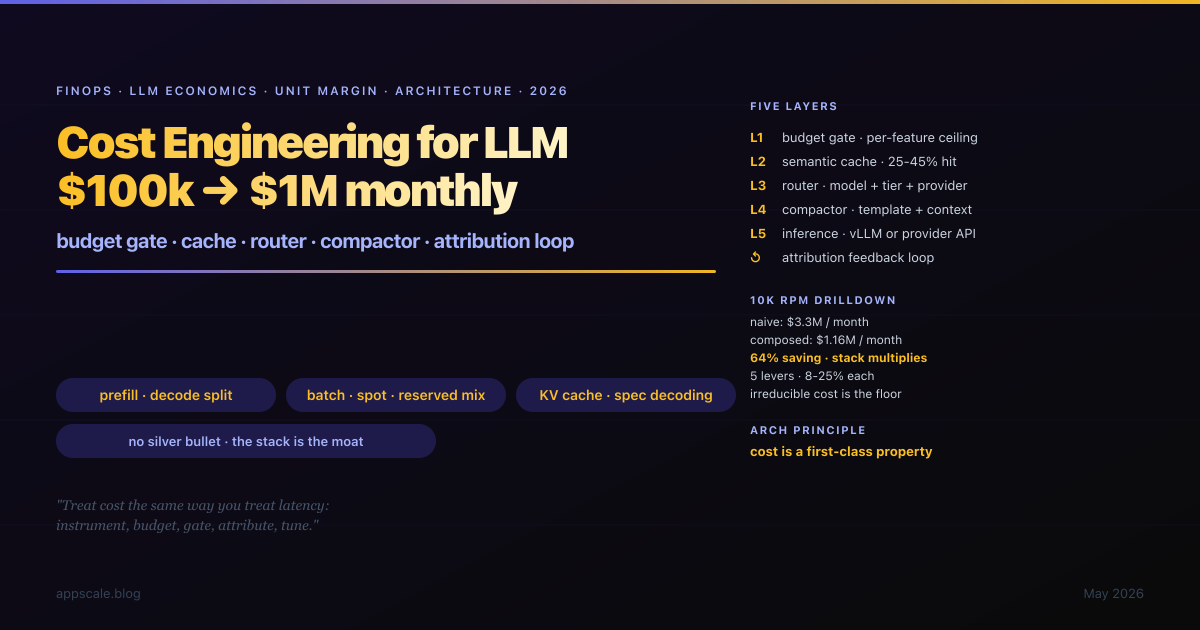
The $100k to $1M monthly LLM-spend transition is the architecturally serious crossing in the life of an LLM product. The teams that handle it well treat cost as a first-class architectural property — instrumented, budgeted, gated, attributed, and tuned — and they build the five-layer stack of budget gate, semantic cache, dynamic router, prompt compactor, and inference layer with an attribution feedback loop wrapped around it. This article is the architecture, the order to build it in, the 10k-RPM unit-economics drill-down that produces a 64% reduction through composed savings, the unglamorous levers (prefill/decode separation, KV-cache reuse, speculative decoding, batch endpoints, output-length discipline), the spot/reserved/on-demand procurement mix, 8 anti-patterns that produce the bad spend curve, and the 5-stage maturity ladder.