Retour au blogai-architecture 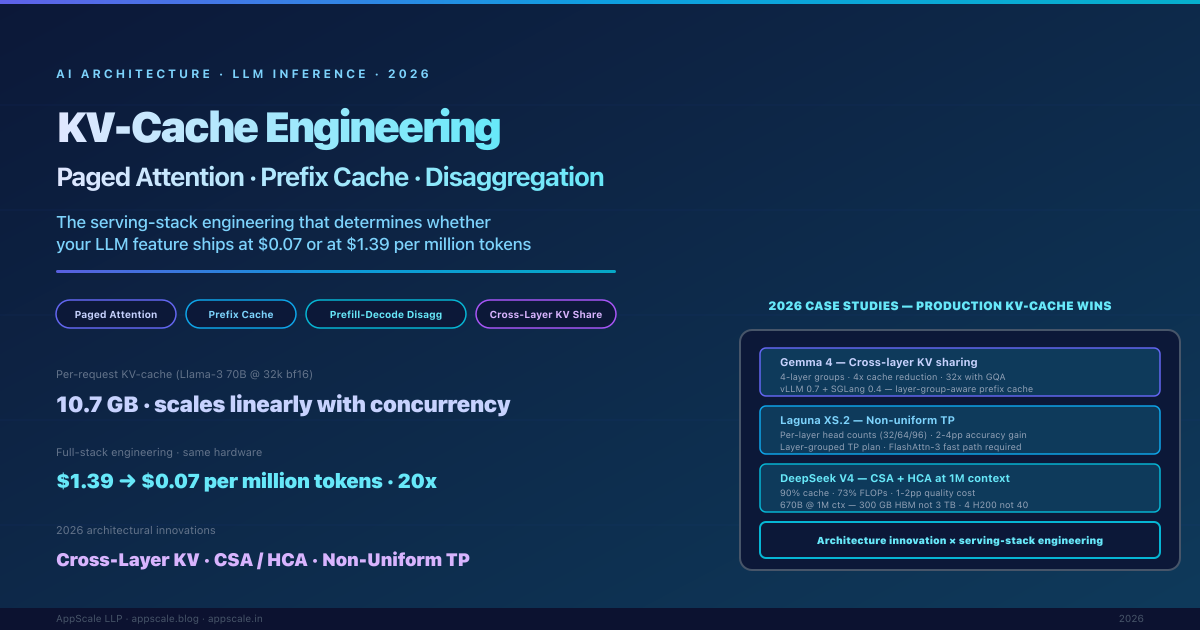
KV-Cache Engineering for LLM Inference: Paged Attention, Prefix Cache, and Prefill/Decode Disaggregation (2026)
kv cache llm inference paged attention vllm sglang tensorrt-llm prefix cache prefill decode disaggregation continuous batching cross-layer kv sharing grouped query attention flash attention speculative decoding gemma 4 deepseek v4 csa hca compression tensor parallelism hbm bandwidth long context inference llm serving stack