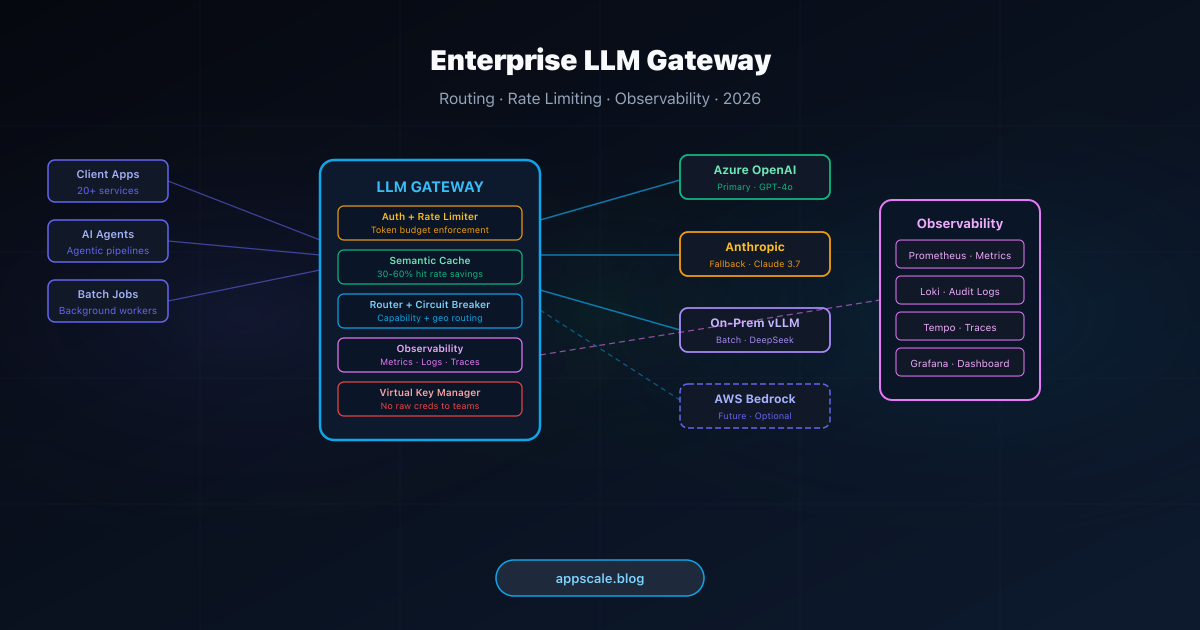
Every mature AI platform running multiple LLM-powered features converges on a single architectural decision: centralise the interface to language model providers. This guide covers the six core functions of a production LLM gateway — routing, rate limiting, circuit breaking, semantic caching, virtual key management, and observability — with implementation patterns and build-versus-buy analysis.