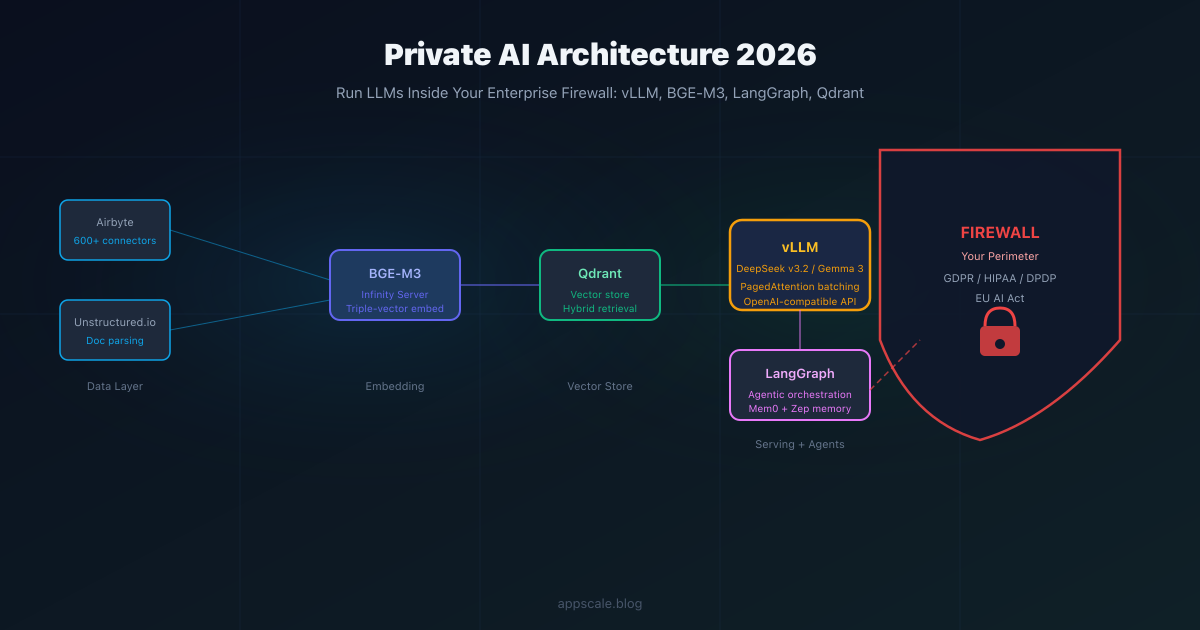
Complete guide to on-premises AI architecture in 2026: open-weight models (DeepSeek v3.2, Gemma 3, Qwen3), vLLM serving, BGE-M3 embeddings, Qdrant, LangGraph, and the Swiss Army Knife vs agent team decision framework.