Инженерные инсайты
Глубокие разборы AI-систем, облачной архитектуры, распределённых систем и инженерного лидерства.

LLM Knowledge Distillation: Teacher-Student Architecture for Smaller, Cheaper Models
Stop paying frontier prices for commodity work. Teacher-student distillation: methods, transfer-set design, the 30-100x cost math, and when not to do it.

How to Build an MCP Server: Tools, Resources, and Production Architecture
A working MCP server fits in 100 lines. Production is the hard part: tool schema design, stdio vs Streamable HTTP, OAuth 2.1, output caps, and audit logging.
Claude Opus 4.8 vs Sonnet 5 vs Fable 5: Which Model for Which Task
Opus 4.8, Sonnet 5, or Fable 5 — official pricing, positioning, and a task-fit decision framework, grounded in Anthropic's own docs, not contradictory third-party leaderboards.
TPU Inference Architecture: Serving LLMs on Trillium with vLLM
GPU is not the only serving option in 2026. TPU (Trillium) cost-per-token, the XLA compilation model, vLLM TPU backends, and agent-driven ops for self-hosted LLMs.

Local-First Architecture: CRDTs, Sync Engines, and Offline-First Apps for 2026
The industry over-corrected toward routing everything through the cloud. Local-first architecture: CRDTs, sync engines, and why apps should work offline by default.

Deep Agents Architecture: Planning, Sub-Agents, and File-System Memory for Long-Horizon Tasks
A simple tool-calling loop collapses on a 100-step task. Deep agents fix it with planning, sub-agents, and a file system as memory — the long-horizon agent pattern.

Prompt Caching Architecture for LLM Apps & Agents: Prefix Caching, Cost, and Latency
Agents and RAG apps re-send the same long prefix every turn. Prompt caching cuts input cost up to ~90% and speeds first tokens — the win most teams leave off.
A/B Testing and Online Experimentation for LLM Features
A higher offline eval score is a hypothesis, not proof. How to run controlled online experiments on prompts, models, and RAG: architecture, metrics, and the statistics.
Vector Index Tuning for Production: HNSW, IVF, and Product Quantization
The index parameters, not the database brand, decide whether RAG answers in 20ms at 95% recall or 200ms at 80%. Tuning HNSW, IVF, and Product Quantization in production.

LLM Quantization for Production Inference: INT8, FP8, AWQ, and GGUF
GPUs dominate self-hosted inference cost. Quantization cuts memory 2-4x for a small accuracy hit: FP8, INT8, AWQ, GPTQ, GGUF, PTQ vs QAT, and when not to do it.

Document Chunking Architecture for RAG: Fixed, Semantic, Late, and Contextual Retrieval
Chunking is the highest-leverage, most-neglected decision in RAG. Fixed vs recursive vs semantic vs late vs contextual retrieval — and the pipeline that ties them together.

Serverless AI Agent Runtime: microVM Lifecycle Architecture for Agent Workloads
Agents are bursty, long-tailed, and untrusted — exactly what an always-on fleet handles worst. A serverless microVM runtime: scale-to-zero, isolation, and cold-start mitigation.

Managed vs Self-Hosted Code Sandboxes: A Build-vs-Buy Decision for AI Code Execution
Should you buy a managed code sandbox or self-host Firecracker yourself for AI code execution? A build-vs-buy decision framework across cost, compliance, and control.

Stateful AI Agent Sandbox Sessions: Pause, Resume & Snapshot with microVMs
Long-running AI agents wait far more than they work. Stateful microVM sandboxes snapshot on idle and resume in milliseconds — full state kept, near-zero idle cost.
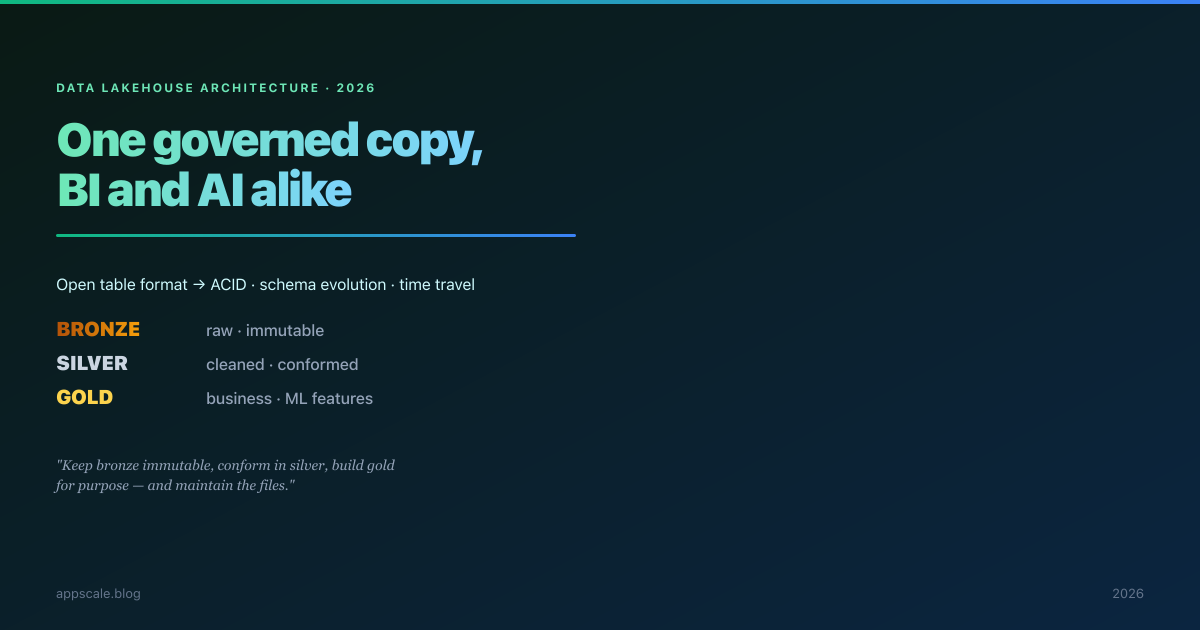
Data Lakehouse Architecture: Iceberg, Delta & the Medallion Pattern
A lakehouse is a warehouse’s table semantics on a lake’s cheap storage, organised by the medallion pattern and kept alive by compaction and governance. How to architect one.

Zero-Downtime Database Migration Architecture: Expand-Contract, Dual-Write & Backfill
Change a production schema with no downtime via expand-contract: add the new shape, dual-write, backfill in batches, verify, switch reads, drop the old. Every step reversible.

Architecting Physical AI Swarms: Edge Inference, Mesh Networking, and Coordinated Autonomy
A physical AI swarm is a moving distributed system with a hostile network. The architecture for edge inference, masterless coordination, resilient mesh comms, and local safety.

Webhook Delivery Architecture: Retries, Idempotency, Signing & Ordering
Webhooks are a distributed-systems problem in an HTTP-POST costume. The producer architecture for at-least-once delivery: retries, dead-letter, HMAC signing, idempotency, ordering.

Vector Database Architecture: Choosing and Scaling pgvector, Pinecone, Qdrant & Weaviate
A vector database is a recall/latency/memory machine behind a similarity-search API. How to choose pgvector, Pinecone, Qdrant, or Weaviate — and what breaks first as it scales.

Fine-Tuning vs RAG vs Prompt Engineering: A Decision Architecture
Fine-tuning, RAG, and prompt engineering answer three different questions — how should it behave, what should it know, what should it be told. A decision architecture.
Оставайтесь впереди
Еженедельные глубокие разборы AI-систем, облачной архитектуры, распределенных систем и инженерного лидерства. Присоединяйтесь к 5,000+ инженерам.