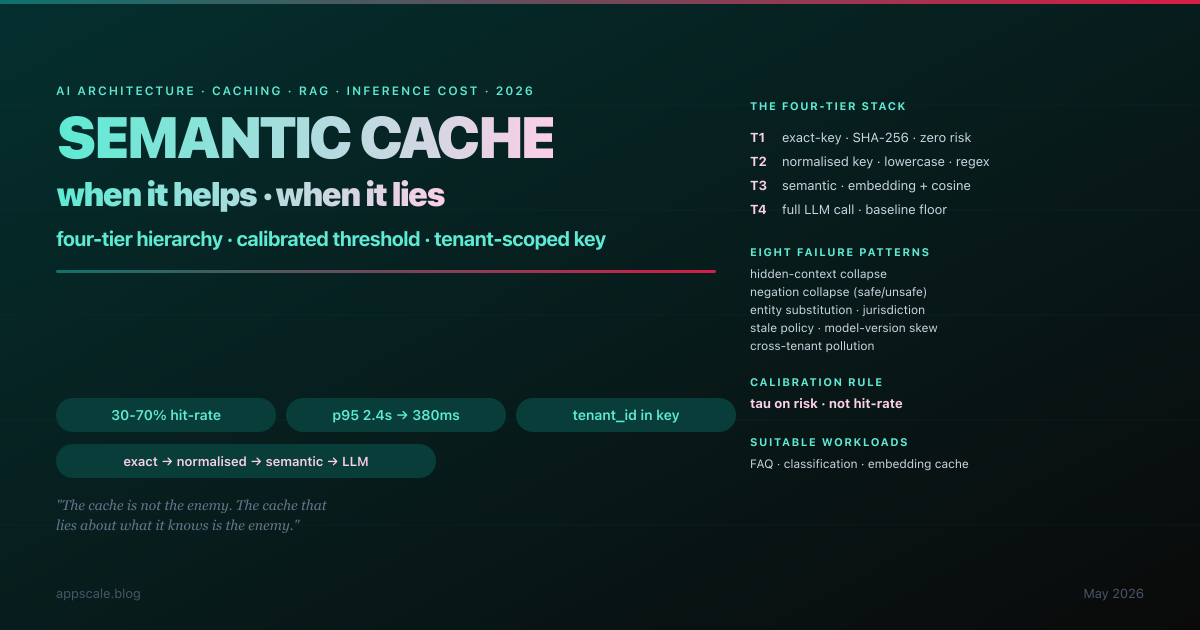
A team running a customer-support assistant on GPT-4o reported a beautiful number to their CFO: 47% cache hit-rate, $18,000 per month saved, p95 latency down from 2.4s to 380ms. Three weeks later the same team was reading a customer-trust incident report. The semantic cache had decided two refund-policy questions were "the same enough" at cosine similarity 0.93 — and 0.93 had been a reasonable threshold on the eval set, which had not contained two refund policies. The cache was not broken; the cache was working exactly as designed. The architecture was wrong. This article is the deep-architecture answer to the question the team had not asked: when does semantic cache help, and when does it lie? Four-tier hierarchy from exact-key through normalised through semantic to LLM, three-step threshold calibration using a risk-weighted decision rule, multi-tenant key design that prevents the cross-tenant-pollution incident, TTL and model-version discipline, eight failure patterns to retire, five-stage maturity ladder, and the Monday-morning checklist that ships sustainable savings without the customer-trust incidents.