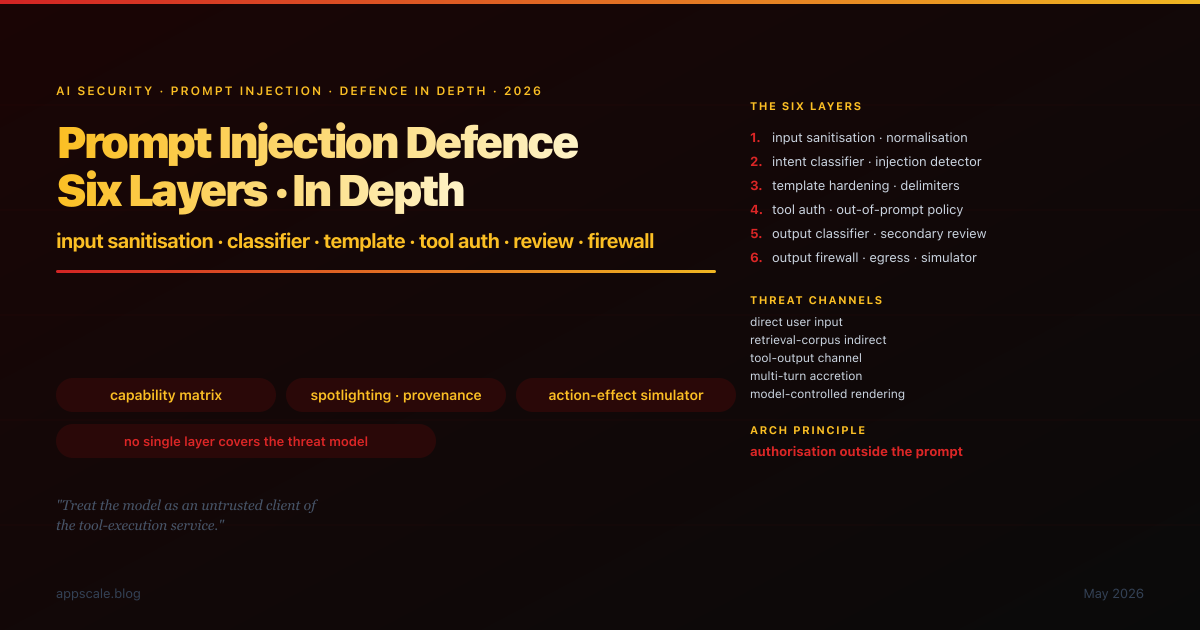
Prompt injection in 2026 is no longer a research curiosity; it is the day-one architectural assumption. The six-layer defence-in-depth stack is the engineering response: input sanitisation and normalisation, intent classifier and injection detector, prompt-template hardening with delimiters and role separation, tool-use authorisation policy outside the prompt, output classifier and secondary review LLM, output firewall for egress filtering and action-effect simulation. This article walks each layer with its threat model, engineering surface, and operational discipline; the build-order rationale; the composition with category-aware guardrails, agent circuit breakers, observability, and incident response. 8 anti-patterns retired, 5-stage maturity ladder, and the honest summary of where the field sits in early 2026.