工程见解
深入探讨人工智能系统、云架构、分布式系统和工程领导力。

Event Sourcing in Production — Snapshots, Projections, and Schema Evolution Without Tears (2026)
Event sourcing for production microservices in 2026 — aggregate boundaries, append-only stores, snapshot strategy, projection rebuilds, and schema evolution.
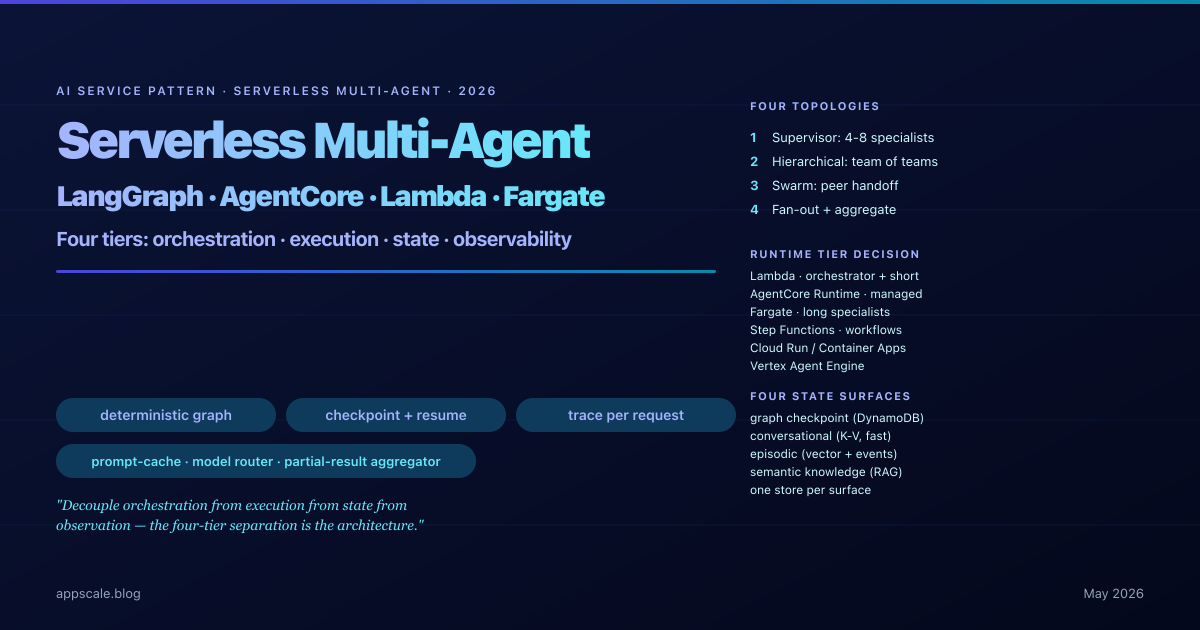
Serverless Multi-Agent Orchestration — LangGraph, Bedrock AgentCore, and the Architecture Pattern Behind Production AI Workflows (2026)
2026 pattern for serverless multi-agent systems: LangGraph orchestration, Bedrock AgentCore, fan-out topologies, four-tier state, per-span observability.

Streaming LLM Response Pattern — SSE, WebSockets, Structured Output, and Backpressure (2026 Architecture)
The 2026 production architecture for LLM streaming: SSE versus WebSockets, structured output, backpressure, end-to-end cancellation, TTFT levers, and proxy buffering.
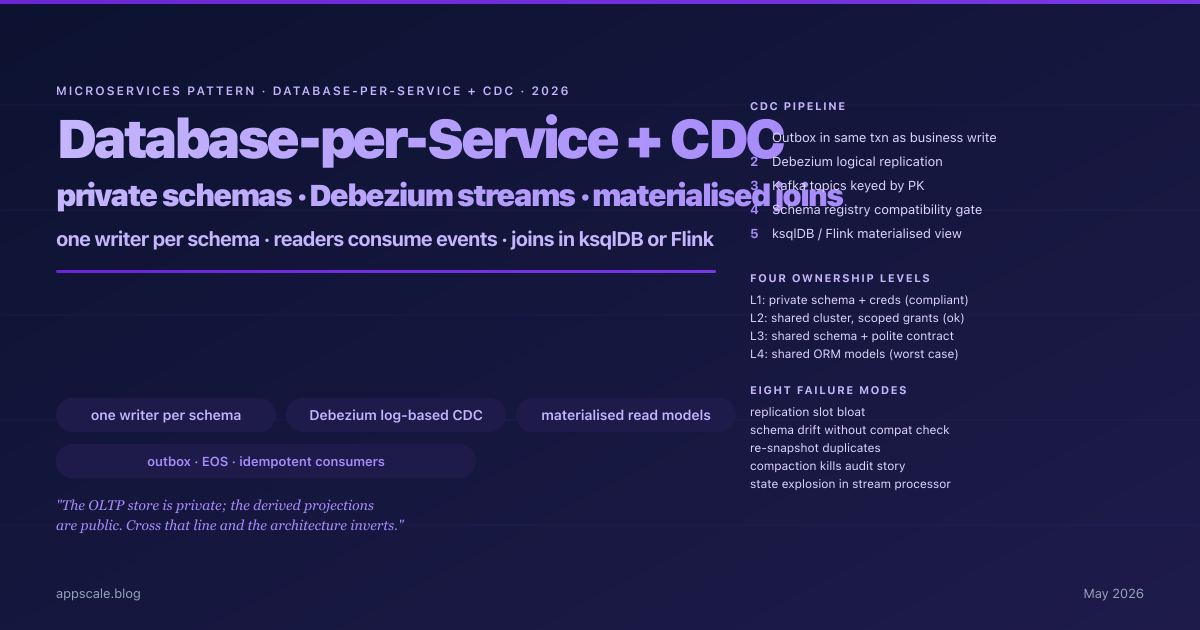
Database-per-Service and Cross-Service Joins with CDC — The 2026 Architecture for Reporting Without Distributed Transactions
The 2026 architecture for database-per-service plus cross-service joins via Debezium CDC, Kafka, and ksqlDB / Flink materialised views — with the operational runbook.

PII Redaction Pipeline Architecture for LLM Workloads — Presidio, NER, and Reversible Tokenisation (2026)
The 2026 architecture for PII redaction in LLM stacks: three-layer detector, regulatory-pack routing, four tokenisation tiers, per-tenant CMK, WORM audit, provenance graph.
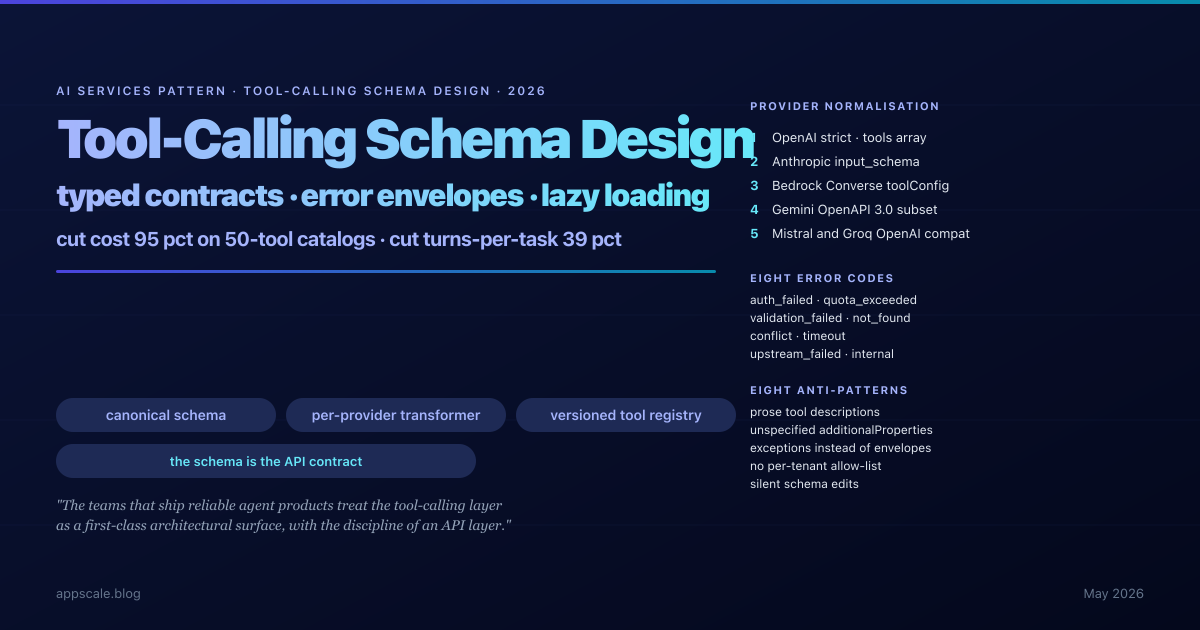
Tool-Calling Schema Design for LLM Agents — The 2026 Production Pattern
Production tool-calling needs typed canonical schemas, eight-code error envelopes, per-tenant allow-lists, and lazy loading. The schema layer pays back at 95% cost cut.

Policy-as-Code Architecture: OPA + Terraform Pattern Library for IaC Governance (2026)
IaC without policy-as-code is a fast lane to misconfigured cloud: every engineer writes Terraform that passes terraform plan, no one writes the controls that say "S3 buckets must be encrypted with customer-managed KMS, must enforce TLS, must deny public read; security groups must not expose port 3389 to 0.0.0.0/0; IAM roles must not have wildcard trust principals". Policy-as-code, expressed as a versioned pattern library of OPA Rego rules evaluated against every Terraform plan in CI/CD, turns the cloud security model from "reviewer caught it" to "the pipeline refused to apply it". This article is the production architecture: the five orthogonal control patterns (required metadata, allowed configuration, exposure restriction, protection enforcement, privilege constraint) that compose into every IaC governance system, three production-grade Rego examples with the failure modes they catch, the pattern library directory layout with shared helpers and test fixtures, the six-stage gated CI/CD pipeline with structured violation reporting, the three-phase rollout (advisory → enforce → operationalize) that protects developer velocity, the OPA vs Checkov vs tfsec vs Conftest decision matrix, the drift bridge to AWS Config / Azure Policy / GCP Security Command Center, and the exception lifecycle with TTL and audit trail that keeps the process from becoming a permanent loophole.

The Retrieval Cache Hierarchy: Embedding, BM25, Dense, Rerank, and Response Caching for Production RAG (2026)
Production RAG is not one cache, it is a five-tier hierarchy — embedding, BM25 posting-list, dense ANN graph, cross-encoder rerank, and final response — each with its own key derivation, hit-rate economics, invalidation contract, and freshness budget. Teams that bolt one Redis layer onto a RAG pipeline keep paying for embedding calls and rerank passes on every request; teams that stratify the cache hierarchy cut cost by 4 to 8x and p99 latency by 5 to 15x on hot workloads while keeping multi-tenant isolation and document-churn invalidation correct. This article is the deep design: why a single response cache fails under reciprocal-rank-fusion non-determinism and prompt-template drift and multi-tenant key leakage, the five tiers and what each one caches, the canonical-query-hash discipline that propagates through every tier, the cross-encoder rerank cache as the largest cost lever, response-cache keying with tenant_id and acl_hash and retrieved-document revision hashes, event-driven invalidation with a reverse index for efficient per-document purge, multi-tenant isolation patterns with cross-tenant CI tests, cost math at 2026 prices showing the 26 to 60 percent saving on customer-support workloads, eight anti-patterns, observability metrics per tier, and the five-stage maturity ladder.
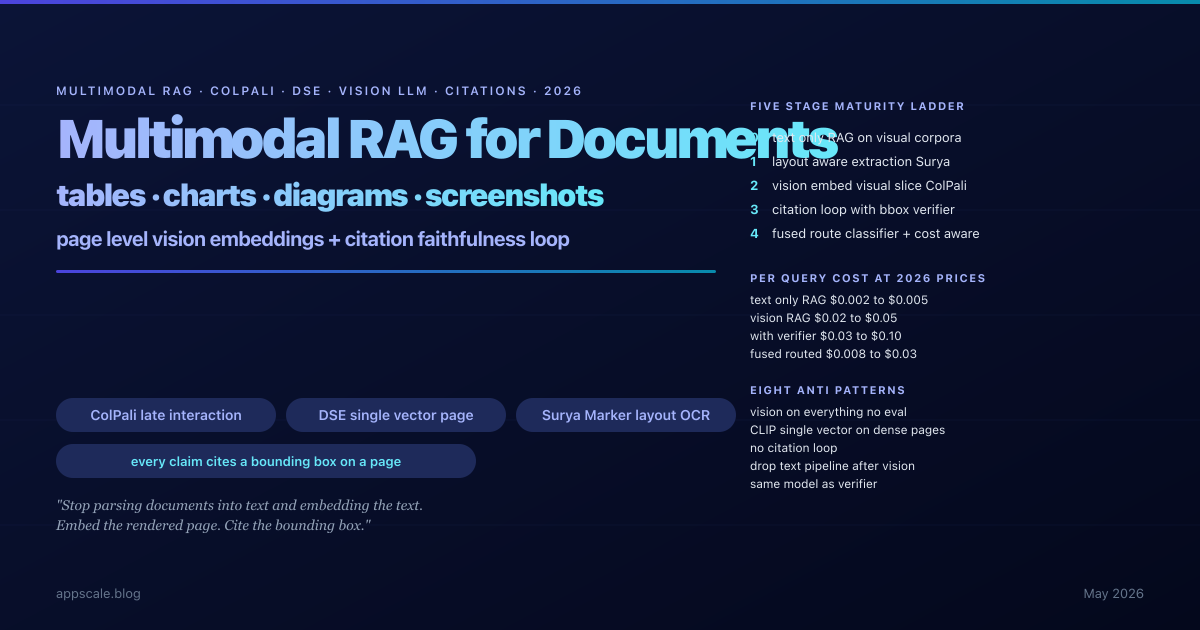
Multimodal RAG for Documents: ColPali, DSE, and Vision-LLM Citation Architecture (2026)
Vector RAG silently fails on PDFs that carry their meaning in tables, charts, schematics, and screenshots, because the parser flattens or erases the very content that holds the answer. ColPali, Document Screenshot Embeddings, and ColQwen2 flipped the parse-first pipeline on its head by embedding the rendered page itself as a sequence of patch vectors with late-interaction MaxSim scoring; the 2026 production multimodal RAG stack composes layout-aware parsing, page-level vision embeddings, hybrid text-plus-visual retrieval routed by a lightweight classifier, and a vision-LLM citation loop that proves every answer back to a bounding box on the source page. This article is the deep-architecture decision guide: when the vision pipeline is justified and when layout-aware extraction is enough, what ColPali and DSE actually do under the hood, the full production pipeline with parse, embed, retrieve, ground stages, the non-negotiable citation faithfulness loop with structured-output generation and per-claim verifier, table and chart understanding patterns, hybrid composition with query classifier and reciprocal rank fusion, cost math at 2026 prices showing the 10x to 25x generation-cost premium and the levers that compose to bring it back down, eight anti-patterns, and the five-stage maturity ladder from text-only RAG to cost-aware composed hybrid.
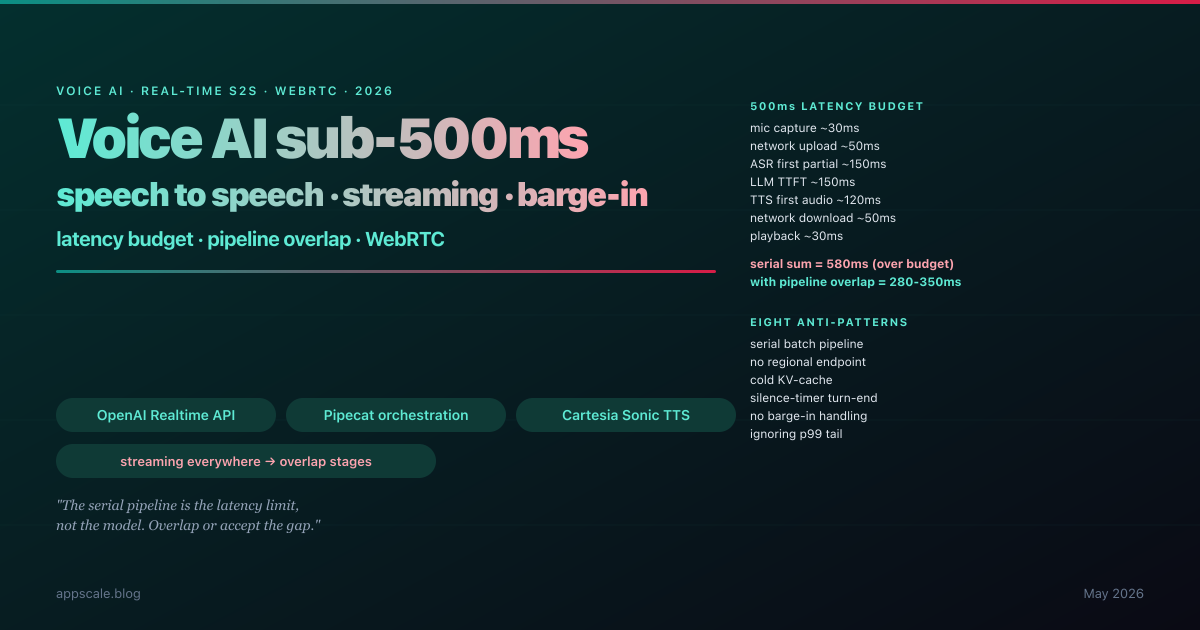
Voice AI Architecture in 2026: How to Hit Sub-500ms Speech-to-Speech Latency Without Faking It
The honest reason most voice AI demos feel awkward in production is latency budget. A human conversational turn-taking gap is roughly 200ms; anything beyond about 800ms feels broken; the comfortable 2026 production target is end-to-end speech-to-speech response under 500ms, measured from the user’s last audio frame to the first audio frame of the agent’s reply. The architectures that hit this in 2026 are not faster models bolted onto the same pipeline; they are streaming end-to-end with first-token TTFT optimisation, barge-in handling, jitter-tolerant transport, and a hard discipline about what runs at the edge versus the cloud. This article is the deep-architecture decision guide: the latency budget broken down stage by stage, why batch ASR plus chat-completion LLM plus offline TTS will never hit the target, OpenAI Realtime API and Gemini Live as integrated speech-to-speech baselines, Pipecat and LiveKit Agents as orchestration layers, barge-in via Silero VAD and turn-end prediction, WebRTC versus WebSocket transport, streaming TTS with ElevenLabs Flash and Cartesia Sonic, eval metrics (WER, latency p50/p99, barge-in latency, turn-taking smoothness), eight anti-patterns, five-stage maturity ladder.
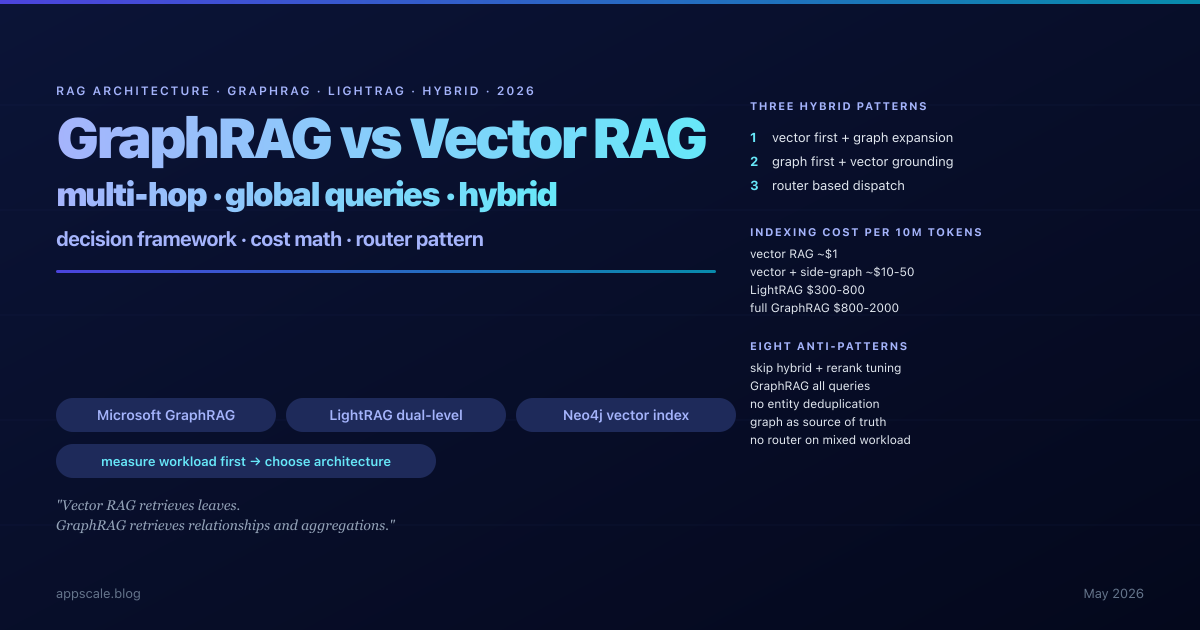
GraphRAG vs Vector RAG vs Hybrid: A 2026 Multi-Hop Retrieval Architecture Guide
The honest reason most production RAG systems plateau is that dense-vector retrieval has no notion of a relationship. The retriever finds top-k cosine-similar chunks and hands them to the model; if the answer requires composing facts across three documents, vector RAG returns only the chunks lexically close to the query and silently drops the bridging fact. Microsoft GraphRAG named this in 2024; LightRAG offered a cheaper alternative in 2025; the 2026 conversation is no longer "should we add a graph" but "which slice of the workload deserves the graph and how do we compose vector and graph without doubling the indexing bill". This article is the deep-architecture decision guide: the multi-hop and global-query failure modes that motivate graphs, what pure vector RAG actually does and the workloads it serves well, the five-stage Microsoft GraphRAG pipeline and its honest cost (300x to 1000x vector indexing), LightRAG and the simpler-cheaper variants, Neo4j vector index for unified storage, three production hybrid architectures (vector-first plus graph expansion, graph-first with vector grounding, router-based dispatch), the decision framework by workload, indexing cost math worked through at 2026 prices, drift and freshness operational patterns, eight anti-patterns, five-stage maturity ladder.
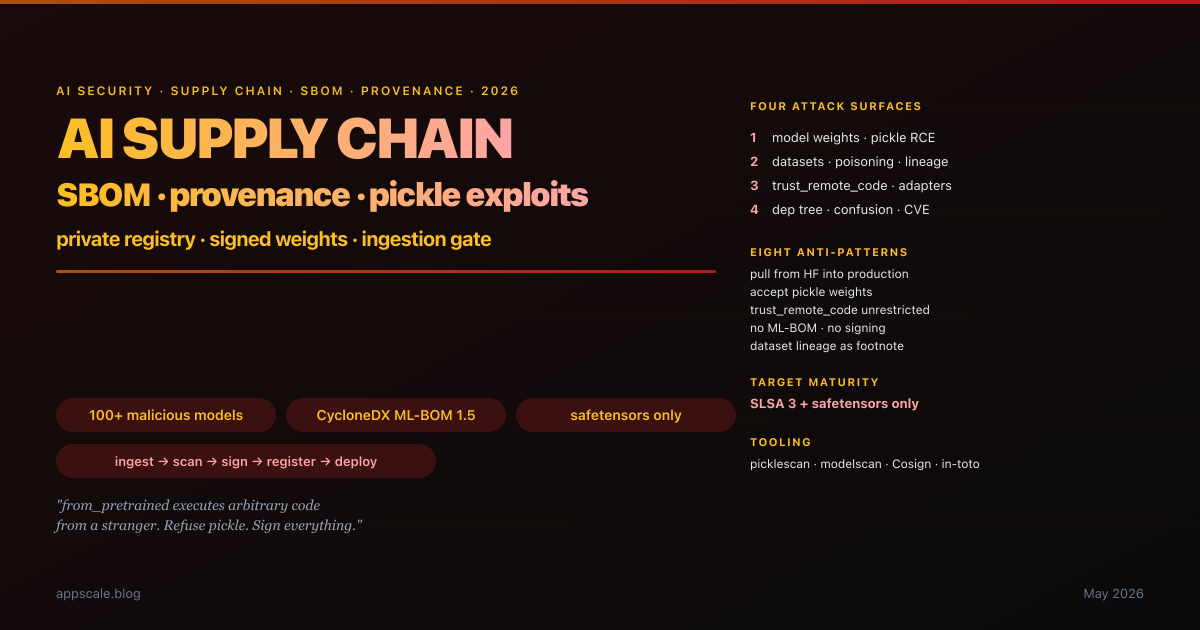
AI Supply Chain Security 2026: SBOM, Model Provenance, and Why That HuggingFace Pickle Is About to Get You Owned
In February 2024 security researchers disclosed that a popular text-classification model on HuggingFace had been quietly modified to execute a reverse-shell payload at import time. Six months later a similar pattern hit a fork of a widely-used embedding model. Twelve months later JFrog disclosed more than a hundred malicious models sitting in plain sight on the public registry. The enterprise response in most cases was a shrug and a reminder to "be careful what you download" — which is the same response the software industry gave to npm and PyPI for a decade before SBOM-and-provenance discipline finally became table stakes. The AI supply chain is the next attack surface. This article is the deep-architecture guide: the four asset categories (weights, datasets, custom-code adapters, dep tree), the pickle problem precisely (why from_pretrained is arbitrary-code execution), the safetensors migration, CycloneDX ML-BOM, Sigstore/Cosign/in-toto for models, the Linux Foundation Model Signing project, the reference ingestion-gate architecture (picklescan + modelscan + CVE scan + provenance verify + private registry + fleet-side signature verification), dependency confusion in ML packages, embedded backdoors and stealth fine-tunes, dataset lineage and the EU AI Act, eight anti-patterns, five-stage maturity ladder, and the Monday-morning checklist.
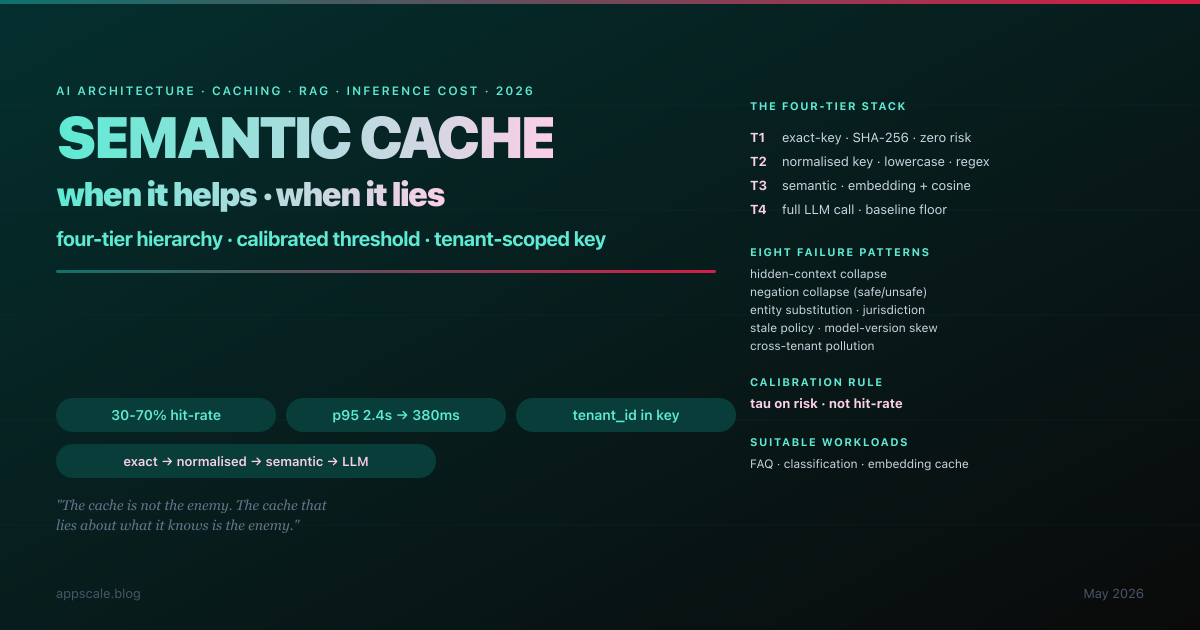
Semantic Cache Pattern: When It Helps, When It Lies — A 2026 Architecture Guide for LLM Features
A team running a customer-support assistant on GPT-4o reported a beautiful number to their CFO: 47% cache hit-rate, $18,000 per month saved, p95 latency down from 2.4s to 380ms. Three weeks later the same team was reading a customer-trust incident report. The semantic cache had decided two refund-policy questions were "the same enough" at cosine similarity 0.93 — and 0.93 had been a reasonable threshold on the eval set, which had not contained two refund policies. The cache was not broken; the cache was working exactly as designed. The architecture was wrong. This article is the deep-architecture answer to the question the team had not asked: when does semantic cache help, and when does it lie? Four-tier hierarchy from exact-key through normalised through semantic to LLM, three-step threshold calibration using a risk-weighted decision rule, multi-tenant key design that prevents the cross-tenant-pollution incident, TTL and model-version discipline, eight failure patterns to retire, five-stage maturity ladder, and the Monday-morning checklist that ships sustainable savings without the customer-trust incidents.

Reasoning LLM Models in Production: o-Series, DeepSeek-R1, Claude Extended Thinking — Architecture, Routing, and Cost (2026)
Reasoning models — o-series, DeepSeek-R1, Claude extended thinking, Gemini deep-think, Qwen QwQ — are the most consequential 2026 LLM development and the most over-applied. Naively routing all traffic through them costs 5-50x more than necessary, adds 5-60 seconds of latency before any visible output, and on a meaningful subset of workloads produces worse answers than the same model family without reasoning. This article is a practitioner reference: what reasoning models actually are (hidden chain-of-thought tokens), the hidden-token cost model with long-tail distributions, when reasoning helps vs hurts vs adds no value, the tiered routing pattern with verifier escalation that delivers frontier quality at workhorse prices, the streamed-reasoning UX patterns, and the eval disciplines that catch regressions on model upgrades.
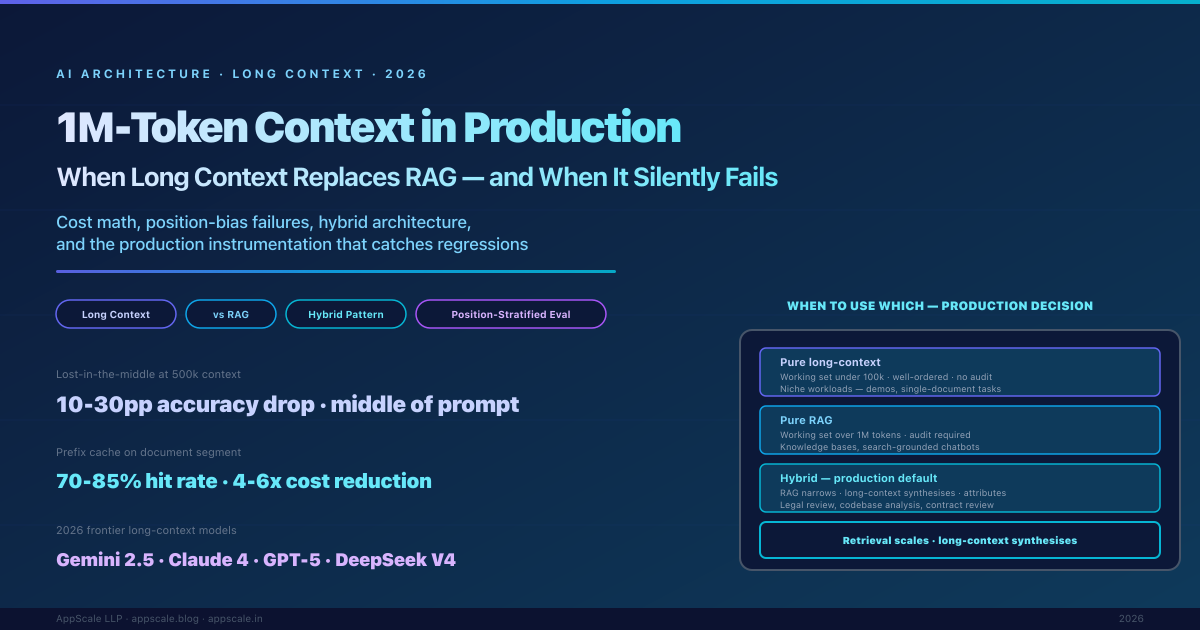
1M-Token Context Windows in Production: Long-Context LLM Architecture vs RAG vs Hybrid (2026)
1M-token context windows are real, useful, and economically viable in 2026 — but only as one tool among several in a hybrid architecture. This article is a practitioner reference for production architecture decisions around long-context: cost math at 1M (dominated by prefill and KV-cache, not output), the well-documented quality failures (needle-in-haystack vs in-distribution distractors, lost-in-the-middle, attention sink, position-bias drift), the decision framework for choosing long-context vs RAG vs hybrid, and the operational instrumentation that catches regressions before customers do. The teams that treat long context as a RAG replacement spend 5-20x more per query than they need to; the teams that treat it as the synthesis layer on top of a retrieval-narrowed working set get the best of both worlds.
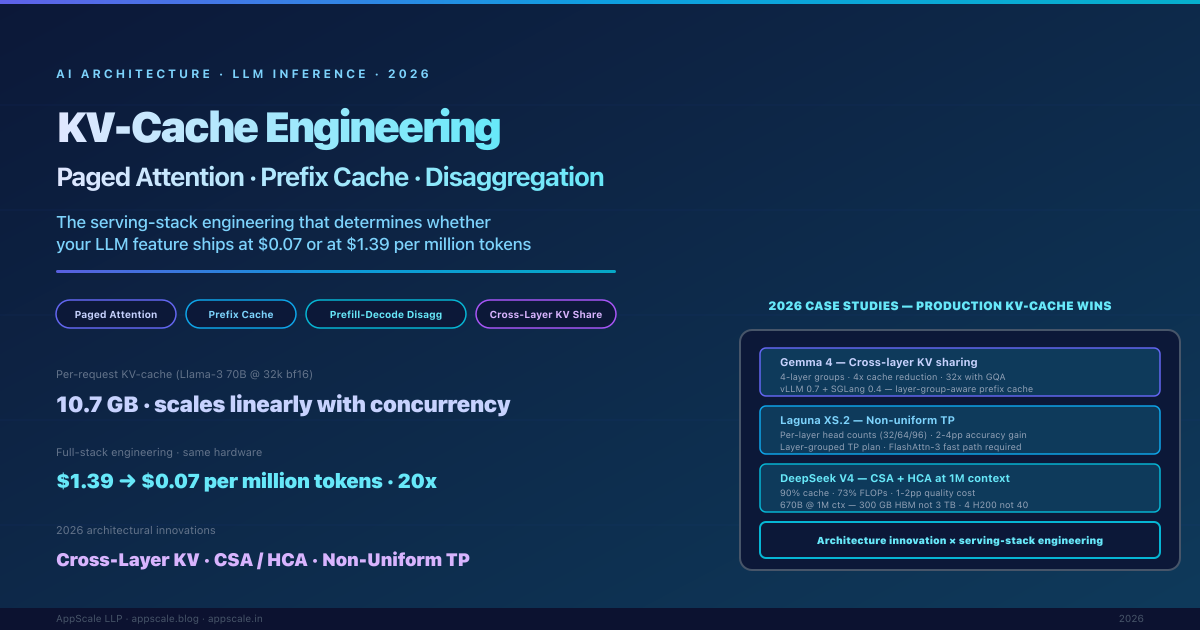
KV-Cache Engineering for LLM Inference: Paged Attention, Prefix Cache, and Prefill/Decode Disaggregation (2026)
The single biggest determinant of whether an LLM feature is economically viable in production is not which model you chose — it is how the KV-cache is managed across the serving stack. This article is a practitioner reference for KV-cache engineering in 2026: paged attention as baseline, prefix caching for RAG hit rates of 70-85%, prefill-decode disaggregation for high-throughput deployments, and three 2026 production case studies (Gemma 4 cross-layer KV sharing in vLLM, Laguna XS.2 non-uniform tensor parallelism, DeepSeek V4 CSA+HCA reducing 1M-context cache by 90%). The compounding effect of the full stack: $1.39 → $0.07 per million tokens on the same physical hardware.

Two-Phase Commit Alternatives: Saga vs TCC vs Outbox vs Reservation-Then-Commit — A Decision Matrix for Distributed Transactions (2026)
Two-phase commit is the wrong default for distributed microservices: it blocks on coordinator failure, requires XA on every participant, holds locks across third-party-API latency, and breaks under network partitions. This article is a decision matrix for the five patterns that have replaced it — Saga, Try-Confirm-Cancel, Outbox, Reservation-Then-Commit, and Idempotency-with-Retry — including a deep treatment of TCC (the alternative most often misimplemented), the four-layer composition stack that production systems actually use, anti-patterns that recreate the 2PC problems, a multi-vendor travel-booking case study, and the trade-off summary that takes a workload description and points at the right combination.
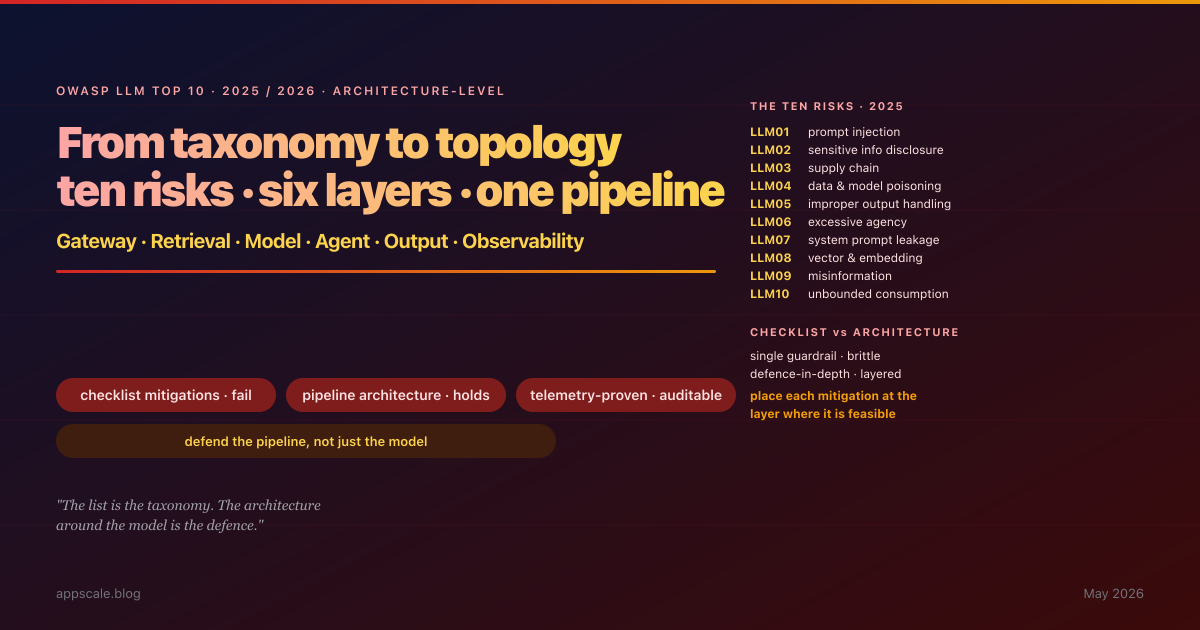
OWASP LLM Top 10 (2025/2026): Architecture-Level Mitigations Mapped to Each Risk
The OWASP Top 10 for LLM Applications gave the industry a shared vocabulary for LLM risk in 2023 and a sharper, incident-evidenced revision in 2025. What it never gave — and was never intended to give — is the architecture that actually contains those risks in production. This article walks the 2025 list, and for each of the ten risks specifies the architectural mitigation that contains it, the topological layer where the mitigation lives (gateway, retrieval, model serving, agent loop, output handling, observability), the telemetry that proves it is working, and the common failure modes when teams treat the list as a checklist rather than a pipeline-architecture specification. New entries in the 2025 revision — System Prompt Leakage (LLM07), Vector and Embedding Weaknesses (LLM08), Unbounded Consumption (LLM10) — are addressed with the same per-risk architectural placement. The article closes with eight anti-patterns and a five-stage maturity ladder from "we read the list" to a continuous adversarial-testing capability that exercises the pipeline daily.

The Model Router Pattern: Cost-, Quality-, and Latency-Aware Routing Across LLM Providers (2026)
The static model choice has become the most expensive architectural decision in a 2026 LLM system. The provider market now spans a 60-200x price spread end to end, the quality gap on the dominant production workload is below the noise floor of A/B telemetry, and the latency profile of frontier models has widened — not narrowed. The Model Router Pattern is the architectural answer: a routing layer that, for every inbound request, chooses the cheapest model on the provider mix whose expected quality and latency clear the workload-specific gate, with a deterministic fallback when the routing decision turns out wrong. This article specifies the three routing axes (cost, quality, latency) and why single-axis routing always degrades, the four router primitives (cascade, classifier, learned, embedding-similarity) and when each is right, the 2026 landscape (Martian, NotDiamond, RouteLLM, Bedrock Intelligent Prompt Routing, OpenRouter Auto, Portkey, LiteLLM), the four-component calibration loop, the cost math with worked per-million-token economics, eight anti-patterns, and the five-stage maturity ladder from "we picked GPT" to a router that contributes a measurable line item to gross margin.

Agentic RAG Architecture: Self-Query, Plan-Execute-Replan, Tool-Augmented Retrieval, and the Validation Loop (2026)
The RAG pipeline that won 2024 — one question, one dense-vector lookup, one LLM call grounded on the top-k — is not the system that ships to production in 2026. The replacement is not bigger embeddings or a better re-ranker; it is the retrieval loop. Agentic RAG composes four architectural primitives: self-query decomposition that turns a multi-part question into a structured plan, plan-execute-replan with explicit iteration budgets that bound the loop, tool-augmented retrieval with a schema-driven router that chooses between dense indexes / SQL / graph / web search, and a validation loop with a sufficiency critic (gate to terminate-or-replan) and a faithfulness critic (deterministic gate before emission). Together they produce a bounded, observable, auditable retrieval agent. This article is the architecture-first playbook: what each primitive does, how they compose, the four failure modes specific to agentic RAG, eight anti-patterns that account for most production incidents, and the five-stage maturity ladder from classical-RAG-with-LLM-wrapper to full audit-grade deployment.
保持领先地位
每周深入探讨人工智能系统、云架构、分布式系统和工程领导力。加入 5,000 多名工程师的行列。