OldKnowledge,New Vessel.
Essays on on-device AI, data sovereignty, and building systems that keep knowledge where it belongs.
Enter the archive →— 00 / ThesisEvery business runs on knowledge older than its software.
Latest Entries
Game Development in the Fable 5 Era: The AI-Assisted Asset and Code Pipeline That Actually Ships
Mobile App Development in the AI Era: On-Device Agents, the New Stack, and What Ships in 2026
The AI Code Verification Bottleneck: Architecture for Reviewing at Generation Speed
WebGPU in Production 2026: The Browser Is Now a GPU Target — Graphics, Compute, and AI Inference
Prompt-Driven Graphics in 2026: Generating 3D and 2D Scenes with AI Without Shipping the Demo
अथ प्रथमोऽध्यायः ॥
विद्या ददाति विनयं विनयाद् याति पात्रताम् ।
पात्रत्वाद्धनमाप्नोति धनाद्धर्मं ततः सुखम् ॥
We digitize centuries-old manuscripts. Then we build with the same discipline.
AppScale's roots are in a quiet project: structuring classical Sanskrit texts into faithful digital form. Extraction, structure, provenance, sovereignty — the same principles now power our client work.
Built for Every Business
Intelligence that never leaves the device
Offline-first, data-sovereign systems — LLMs, vector search, inference at the edge.
02Document IntelligenceAir-gapped document vaults
Sealed, searchable, provable.
03AI ProductsFull-cycle AI product builds
Mobile-first, production-grade.
04MCP & AI SecuritySecuring the agentic stack
Tool poisoning, prompt injection, confused deputies — studied and hardened.
05Indic Language AIOCR for scripts the world forgot
Sovereign OCR for Indic scripts.
06Consulting & Architecture19+ years shipping at scale
OTT, e-commerce & mobility platforms serving millions.
Game Development in the Fable 5 Era: The AI-Assisted Asset and Code Pipeline That Actually Ships
A three-person team can now scope a fifteen-person game — if the build runs as a pipeline. AI-assisted game dev in the Fable 5 era: direction bibles, verification gates, playtests.
Mobile App Development in the AI Era: On-Device Agents, the New Stack, and What Ships in 2026
The AI feature demos on the founder’s flagship — and 60% of users can’t run it. The 2026 mobile stack: on-device models, hybrid routing, agents, battery budgets, fallbacks.
The AI Code Verification Bottleneck: Architecture for Reviewing at Generation Speed
Your team merges AI code faster than anyone can review it — and trust breaks first. The verification pyramid, blast-radius tiers, and org design for reviewing at generation speed.
WebGPU in Production 2026: The Browser Is Now a GPU Target — Graphics, Compute, and AI Inference
WebGPU hit baseline: compute shaders and AI inference in the browser, 10-15x on compute work. The production architecture — engine vs raw API, fallback ladders, in-page ML.

Prompt-Driven Graphics in 2026: Generating 3D and 2D Scenes with AI Without Shipping the Demo
Prompt a running 3D scene into existence in minutes — then watch it leak memory in production. The generate-direct-engineer pipeline that makes AI graphics shippable in 2026.

PixiJS vs Three.js in 2026: Choosing Your Web Graphics Engine Before It Chooses Your Roadmap
Neither engine is better — one is 3D, one is 2D, and picking the mismatch costs a rewrite. PixiJS vs Three.js in 2026: the decision table, roadmap tiebreakers, and WebGPU on both.
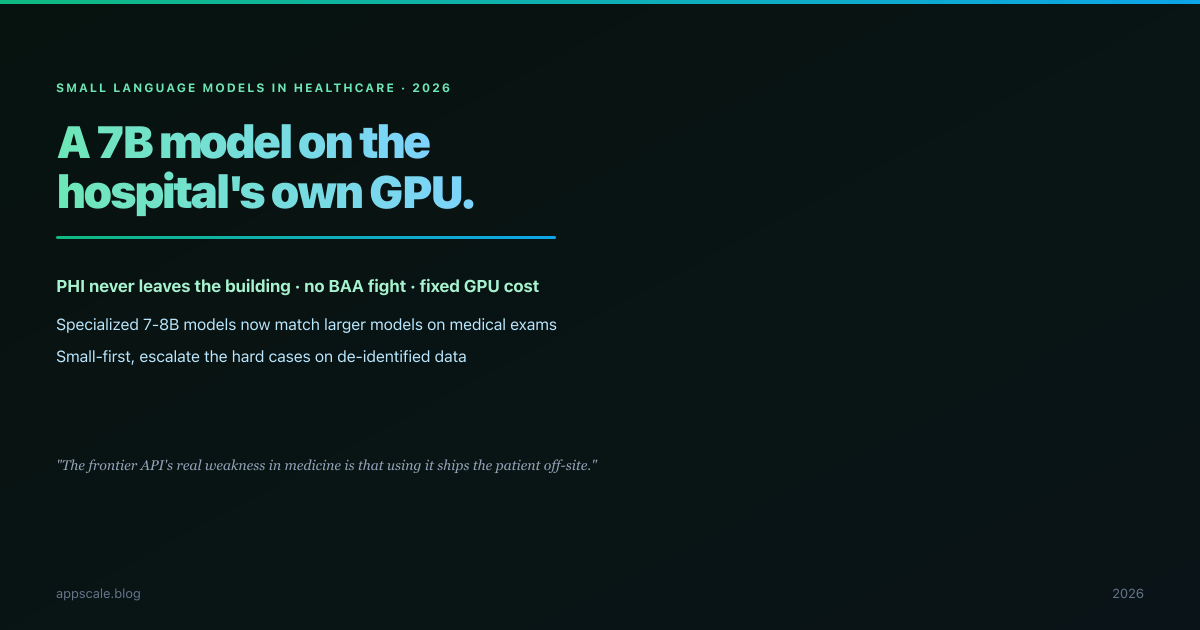
Small Language Models in Healthcare 2026: Private, On-Prem Clinical AI That Fits Inside the Hospital
A specialized 7B model on the hospital’s own GPU never ships PHI off-site — and now matches larger models on medical exams. The private, on-prem clinical-AI architecture for 2026.
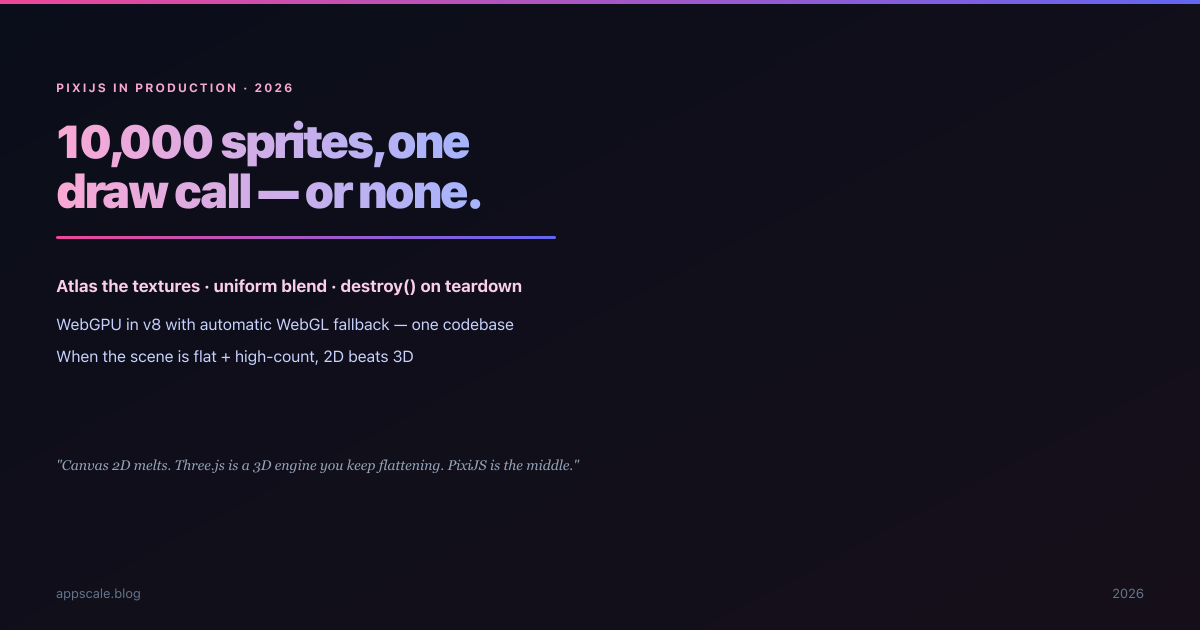
PixiJS in Production 2026: High-Performance 2D Web Graphics, WebGPU, and When 2D Beats 3D
The 2D particle scene flew on the laptop and melts on a real phone. PixiJS in production 2026: sprite batching, texture atlases, memory disposal, and WebGPU with WebGL fallback.

Three.js in Production 2026: WebGPU, Realtime, and the New Web-Graphics Standard
The 3D prototype hit 120fps on the laptop and crawls on a real phone. Three.js in production 2026: draw calls, memory disposal, asset pipelines, and WebGPU with fallback.
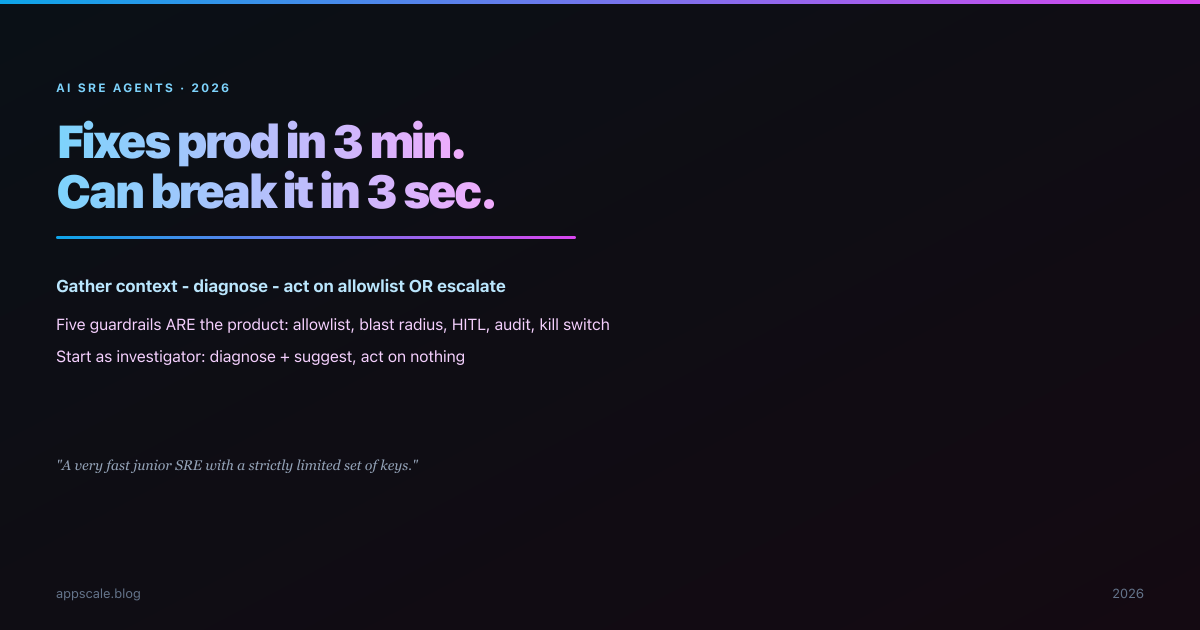
AI SRE Agents: Architecture for Autonomous Incident Response
The same agent that mitigates an incident in 3 minutes can cause one in 3 seconds. AI SRE agents: the diagnose-and-remediate loop, the five guardrails, and where to start.
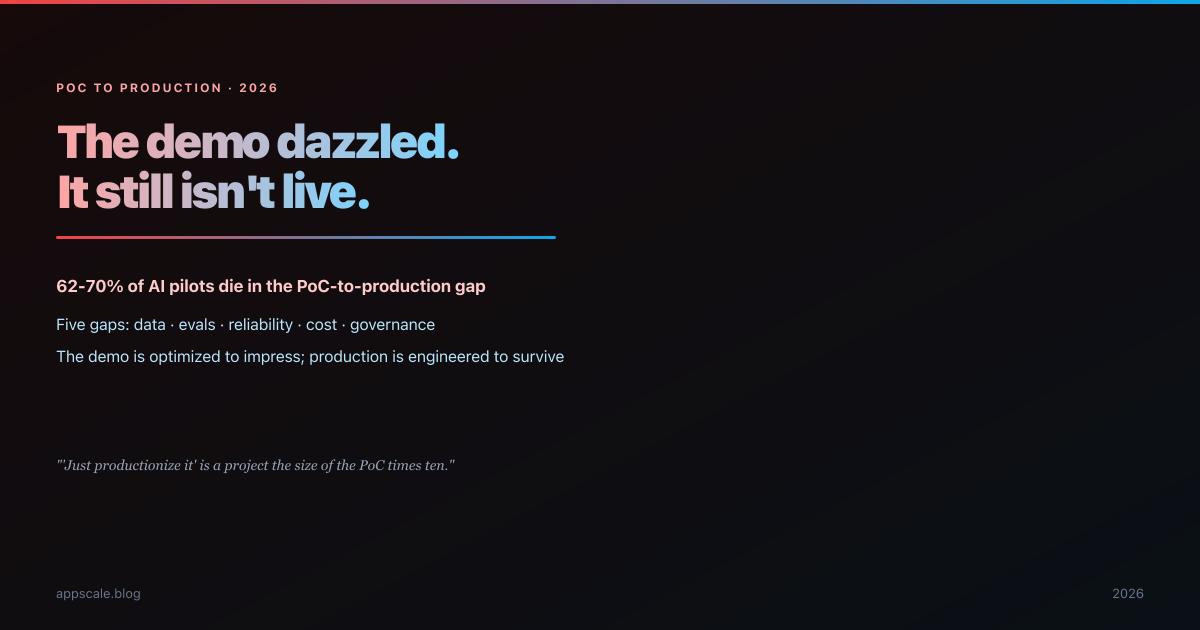
Why AI Proofs-of-Concept Die Before Production (and the Architecture That Ships)
The demo dazzled the board; six months later it still is not live. Why 62-70% of AI pilots die in the PoC-to-production gap, the five gaps, and the architecture that ships.
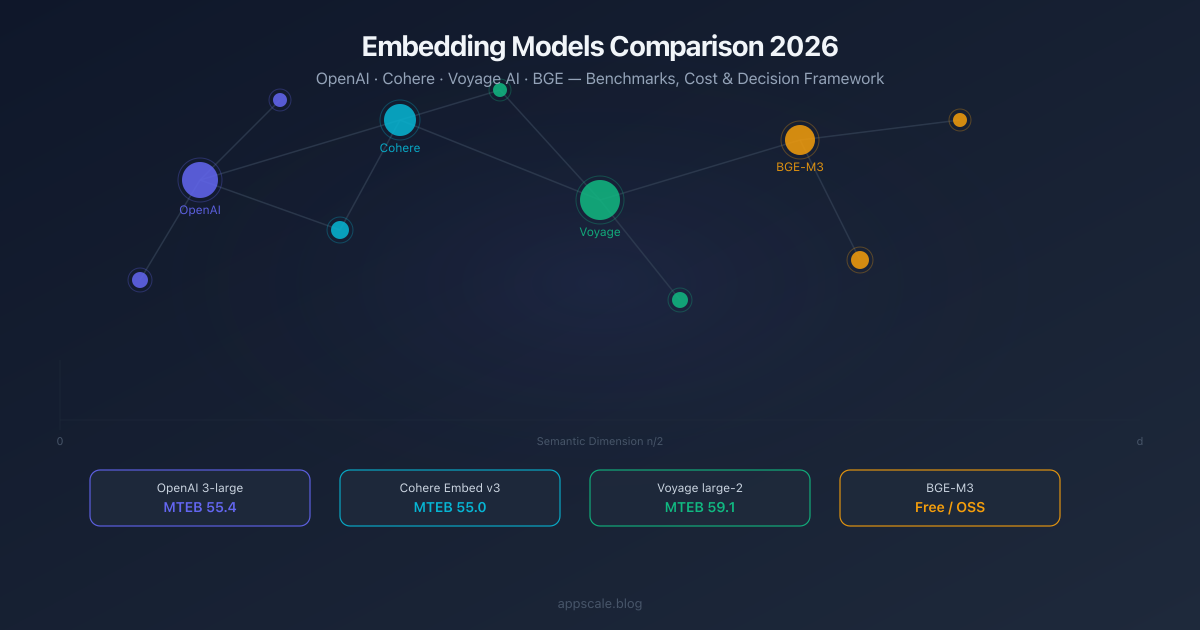
Embedding Models Comparison 2026: OpenAI vs Cohere vs Voyage vs BGE
Head-to-head comparison of the top embedding models in 2026: OpenAI text-embedding-3, Cohere Embed v3, Voyage AI, and BGE. Benchmarks, cost per 1M tokens, context windows, and a decision framework for RAG, code search, multilingual, and self-hosted deployments.
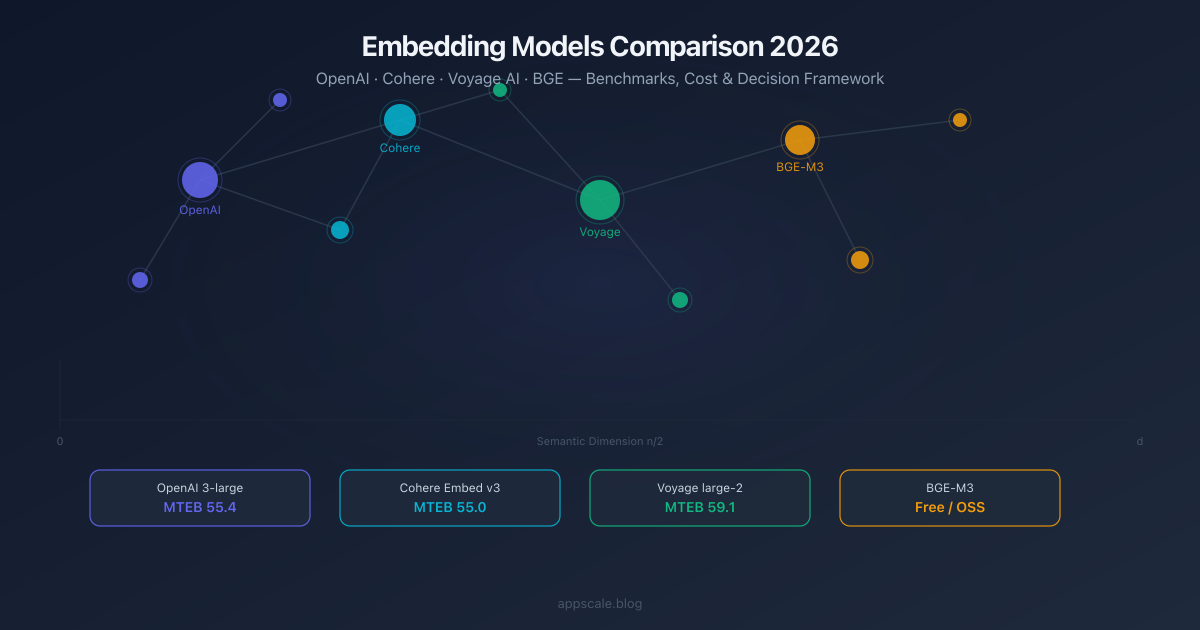
Embedding Models Comparison 2026: OpenAI vs Cohere vs Voyage vs BGE
Head-to-head comparison of the top embedding models in 2026: OpenAI text-embedding-3, Cohere Embed v3, Voyage AI, and BGE. Benchmarks, cost per 1M tokens, context windows, and a decision framework for RAG, code search, multilingual, and self-hosted deployments.
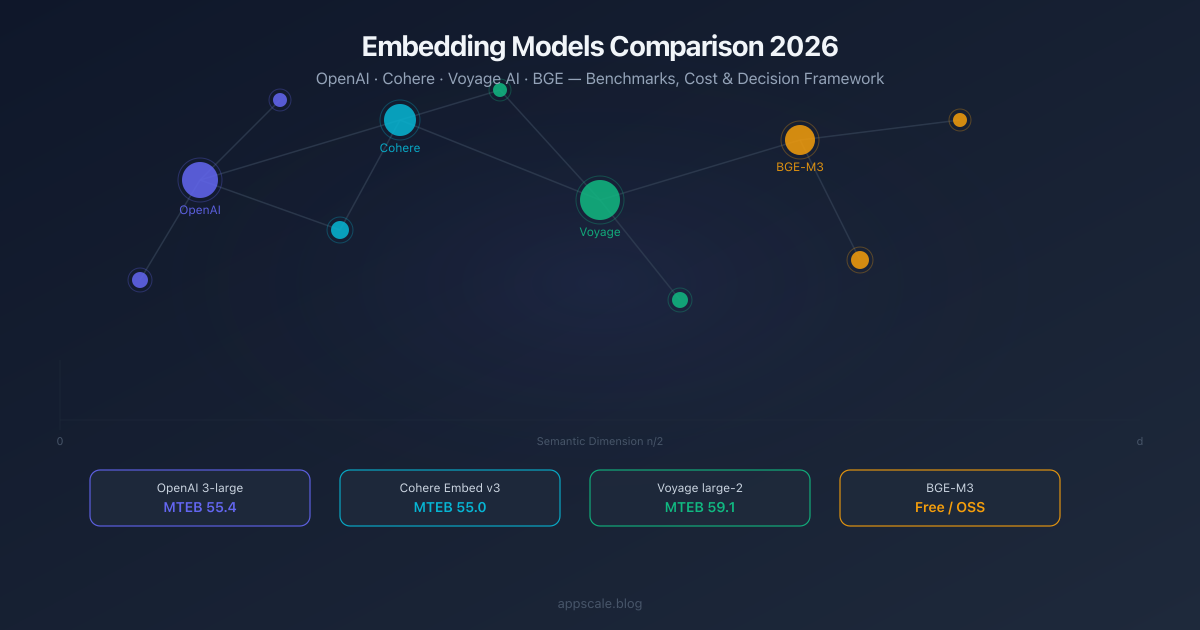
Embedding Models Comparison 2026: OpenAI vs Cohere vs Voyage vs BGE
Head-to-head comparison of the top embedding models in 2026: OpenAI text-embedding-3, Cohere Embed v3, Voyage AI, and BGE. Benchmarks, cost per 1M tokens, context windows, and a decision framework for RAG, code search, multilingual, and self-hosted deployments.
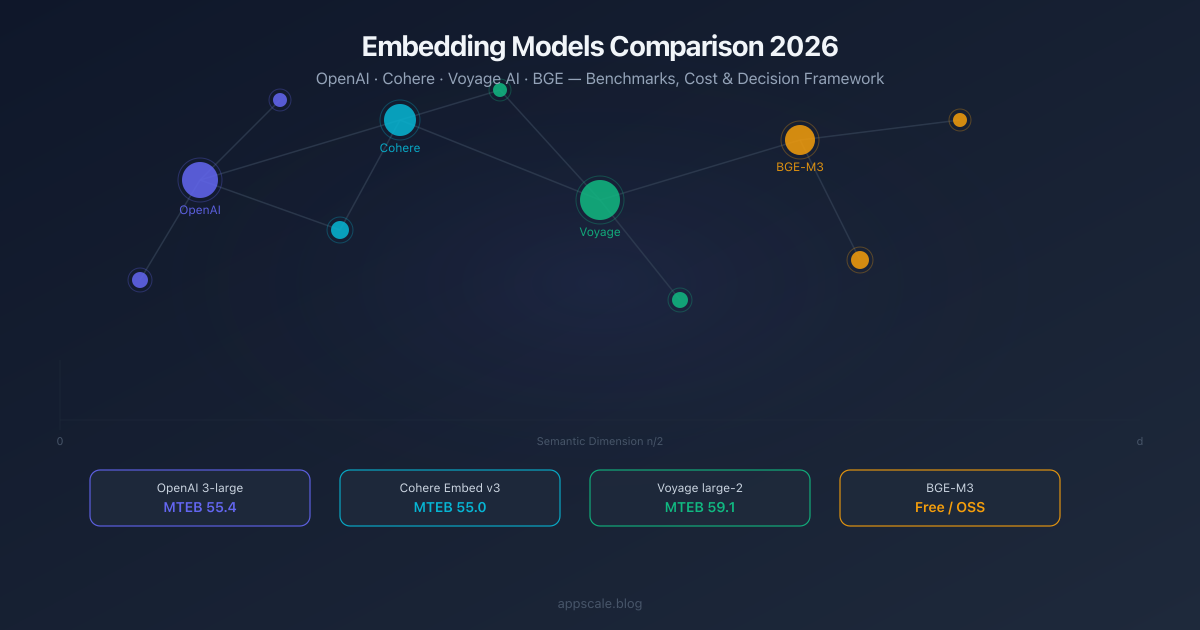
Embedding Models Comparison 2026: OpenAI vs Cohere vs Voyage vs BGE
Head-to-head comparison of the top embedding models in 2026: OpenAI text-embedding-3, Cohere Embed v3, Voyage AI, and BGE. Benchmarks, cost per 1M tokens, context windows, and a decision framework for RAG, code search, multilingual, and self-hosted deployments.

KV-Cache Offloading: Serving 10x More Users by Not Recomputing
Your GPU re-prefills the same 15,000-token prompt ten thousand times a day. KV-cache offloading to DRAM and NVMe turns that recompute into a cheap fetch — 10x users.

Feature Flag Architecture: Rollouts, Kill Switches, and Flag Debt
Ship code to production without releasing it to everyone. Feature flags done right: release vs kill-switch types, sticky rollouts, failure defaults, and killing flag debt.
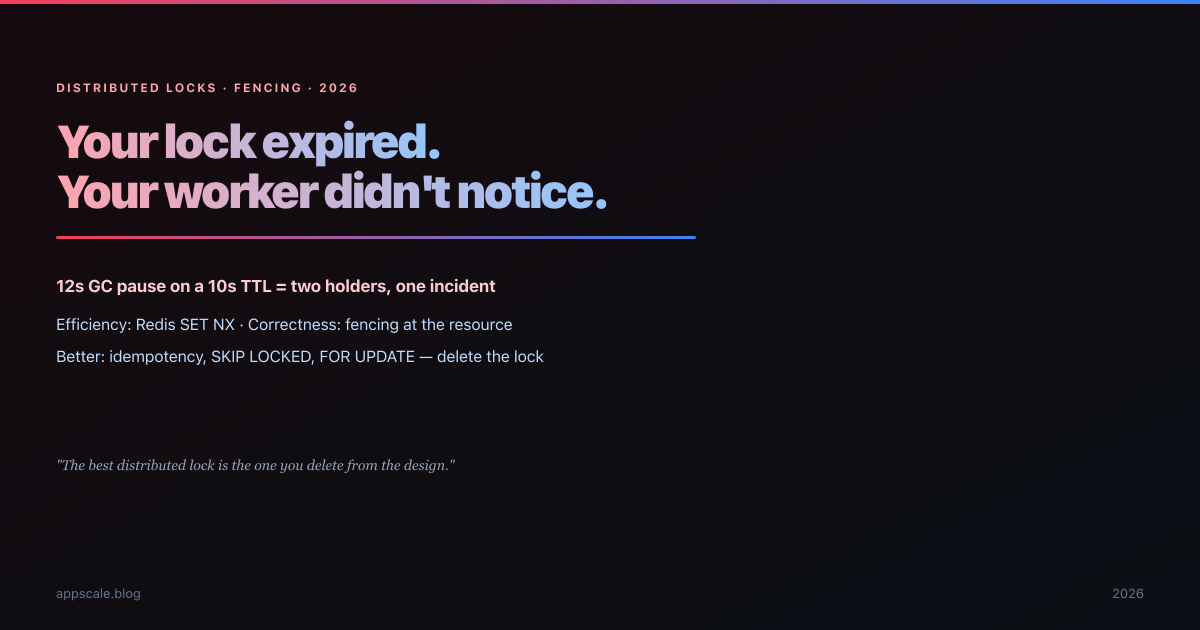
Distributed Locks: Redlock, Fencing Tokens, and Why Your Lock Doesn't Lock
A billing system double-charged 14 customers through a lock that worked exactly as documented. Redlock, fencing tokens, advisory locks, and when to delete the lock.
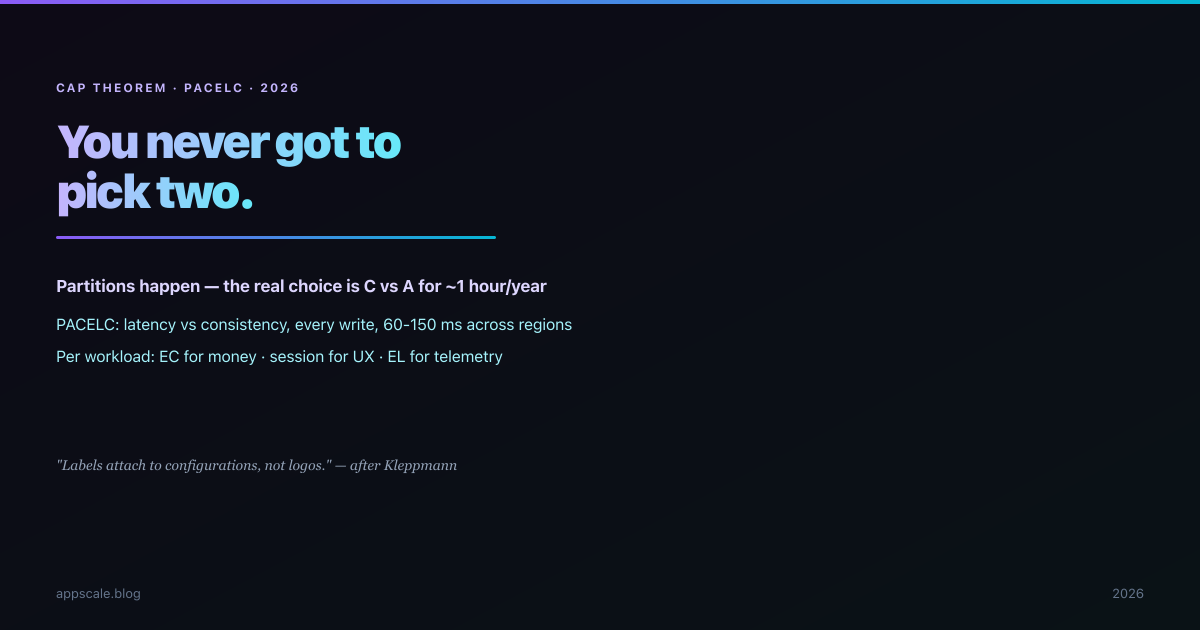
The CAP Theorem, PACELC, and What Real Databases Actually Choose
The pick-two triangle is a misunderstanding: partitions happen regardless. PACELC, quorum arithmetic, and what DynamoDB, Spanner, and Postgres actually choose.

Connection Pooling: PgBouncer, RDS Proxy, and the Serverless Postgres Problem
A team raised max_connections from 100 to 5,000 and throughput fell. Connection pooling done right: PgBouncer modes, RDS Proxy, sizing math, and the serverless trap.
Bring this thinkingto your business.
conversation
One essay, most weeks. No noise.